---
title: "Analiza društvenih mreža u istraživanju masovne komunikacije"
prefer-html: true
---
```{r}
#| label: setup
#| include: false
library(igraph) # temeljni paket za kreiranje, manipulaciju i analizu mreža
library(ggraph) # vizualizacija mreža na temelju ggplot2 sustava
library(tidygraph) # manipulacija mrežnih podataka u tidy formatu
library(ggplot2) # sustav za vizualizaciju podataka
library(dplyr) # manipulacija podataka
library(tidyr) # preoblikovanje podataka
library(knitr) # generiranje tablica u dokumentu
library(kableExtra) # napredno oblikovanje tablica
# Postavke za grafove
theme_set(theme_minimal(base_size = 12))
```
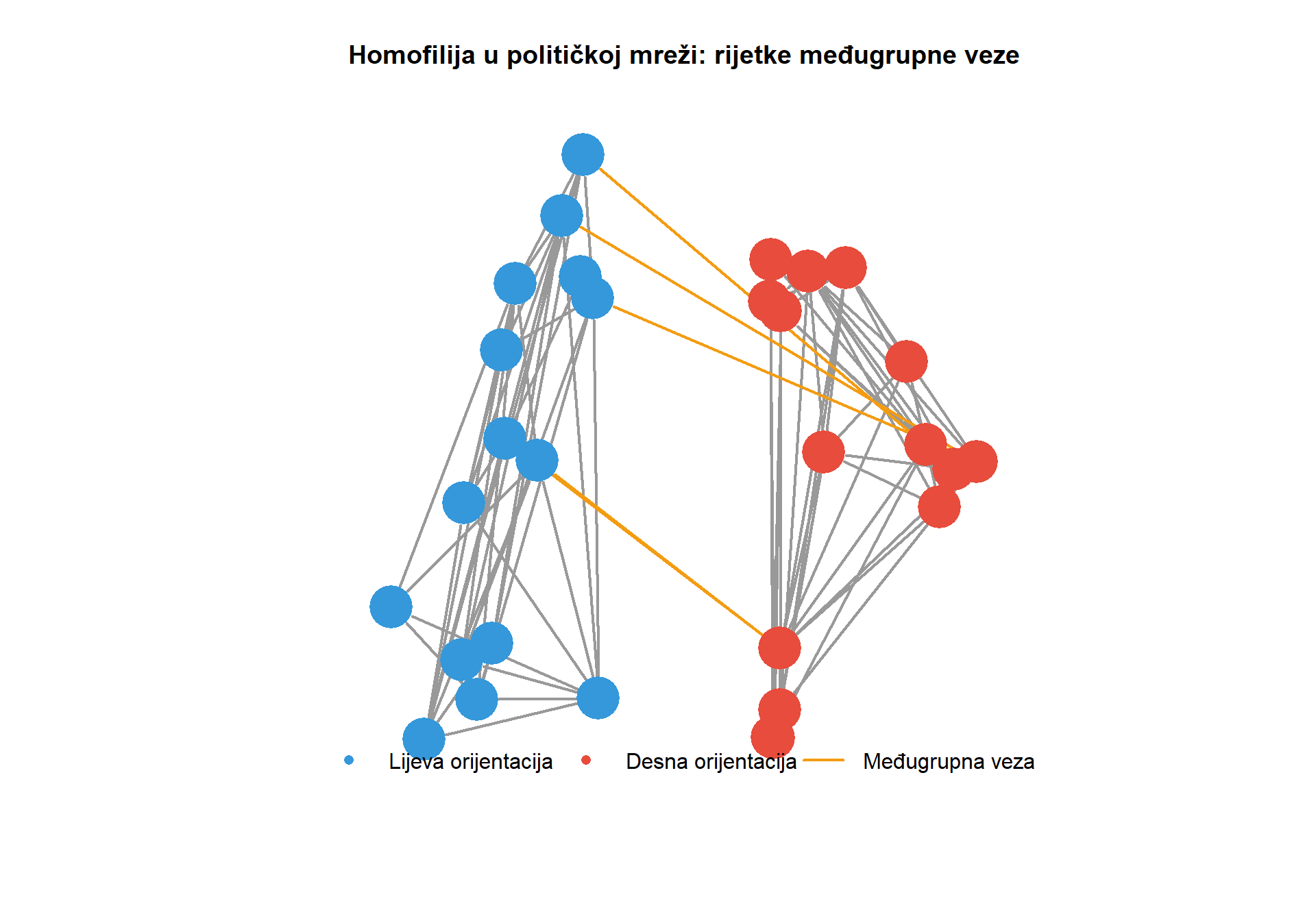
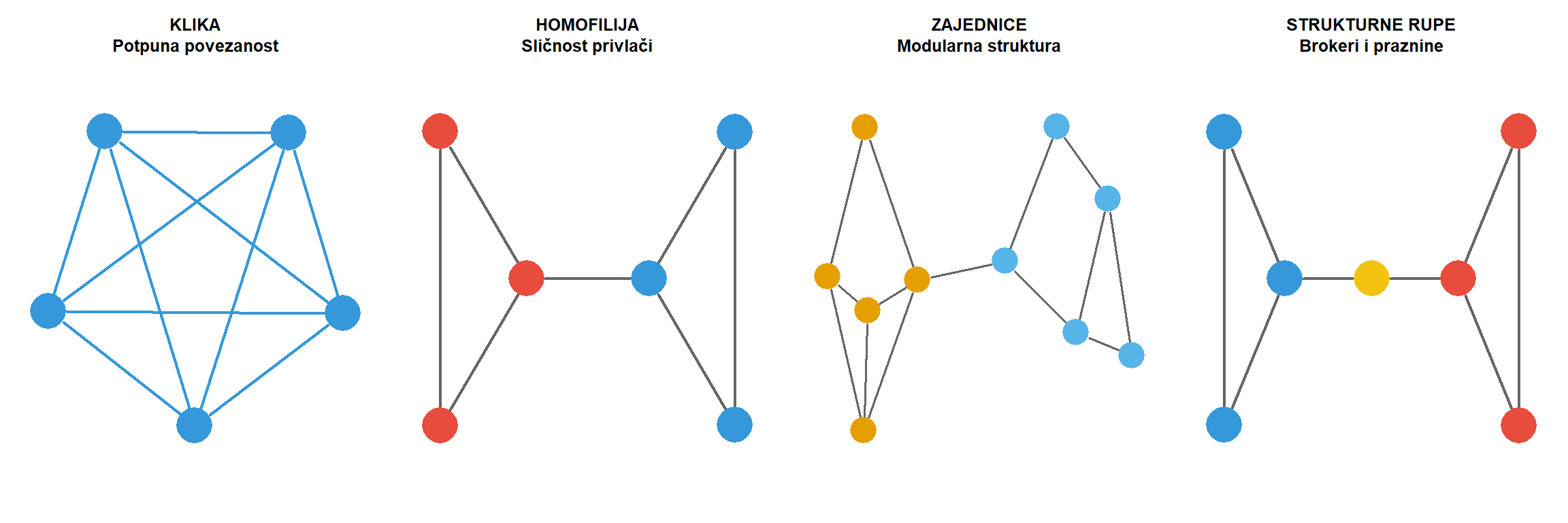
Zamislimo istraživačicu koja želi razumjeti kako su se dezinformacije o izbornim rezultatima proširile hrvatskim digitalnim prostorom u svega nekoliko sati. Pred njom su podaci o tisućama korisničkih računa i desetcima tisuća dijeljenih objava, no sama količina podataka ne otkriva ono što je zapravo ključno: strukturu odnosa kroz koju su se te poruke kretale. Tko je prvi podijelio spornu objavu? Koji su korisnici djelovali kao mostovi između zatvorenih ideoloških zajednica? Postoje li uski prolazi kroz koje je morala proći svaka informacija da bi dosegla širu javnost? Odgovori na ta pitanja ne nalaze se u atributima pojedinih korisnika, poput broja pratitelja ili učestalosti objavljivanja, već u samoj arhitekturi veza među njima. Upravo tu počinje analiza društvenih mreža kao metodološki pristup.
**Analiza društvenih mreža** predstavlja skup teorijskih koncepata i analitičkih postupaka koji omogućuju sustavno proučavanje odnosa i struktura povezanosti među akterima. Za razliku od klasičnih pristupa koji promatraju pojedince i njihove atribute izolirano, mrežna perspektiva polazi od pretpostavke da su društveni fenomeni inherentno relacijski, tj. da nastaju, održavaju se i mijenjaju kroz interakcije među akterima. U kontekstu istraživanja masovne komunikacije, to znači da se širenje vijesti, oblikovanje javnog mnijenja, dinamika dezinformacijskih kampanja ili strukturni odnosi moći u medijskom sustavu ne mogu u potpunosti razumjeti bez mapiranja obrazaca povezanosti među relevantnim akterima. Ovaj pristup nadopunjuje metode prikupljanja podataka obrađene u prethodnim poglavljima, posebice anketu (poglavlje 4) i analizu sadržaja (poglavlje 5), pružajući strukturnu dimenziju koja nadilazi analizu individualnih atributa.
Za provedbu mrežnih analiza u primjerima koji slijede koriste se tri međusobno komplementarna R paketa. Paket `igraph` služi kao temeljni alat za kreiranje mrežnih objekata, izračun mjera centralnosti i drugih mrežnih metrika te primjenu algoritama za detekciju zajednica. Paket `tidygraph` omogućuje manipulaciju mrežnih podataka u *tidy* formatu poznatom iz paketa `dplyr`, čime se mrežni objekti mogu obrađivati istom logikom koja se koristi za tablične podatke. Paket `ggraph` nadograđuje `ggplot2` sustav za vizualizaciju i omogućuje izradu grafički kvalitetnih mrežnih dijagrama. Alternativno, u ekosustavu programskog jezika Python najrašireniji je paket `networkx` koji nudi slične funkcionalnosti. Valja napomenuti da su, za razliku od metoda računalne analize teksta obrađenih u poglavlju 11, metode mrežne analize u načelu jezično neovisne jer operiraju nad strukturnim podatcima o vezama među akterima, a ne nad jezičnim sadržajem. Jezično specifični izazovi pojavljuju se jedino kada se mrežni podatci konstruiraju iz tekstualnih izvora, primjerice pri izgradnji mreža supojavljivanja riječi ili mreža citiranja iz korpusa tekstova, pri čemu se primjenjuju postupci pripreme teksta opisani u poglavlju 11.
Poglavlje je organizirano u šest tematskih cjelina koje postupno grade razumijevanje mrežnog pristupa. U prvom odjeljku razmatra se relacijska perspektiva kao teorijski temelj mrežne analize, uključujući povijesni razvoj od Morenove sociometrije do suvremene mrežne znanosti. Drugi odjeljak uvodi osnovne elemente mrežnih podataka, tj. čvorove, veze, usmjerenost i težinu, te objašnjava načine formalnog prikaza mrežne strukture putem matrica susjedstva i lista bridova. Treći odjeljak detaljno obrađuje mjere centralnosti, od stupnja i međuposredovanja do bliskosti i svojstvene vektorske centralnosti, pokazujući kako svaka od tih mjera operacionalizira različit koncept važnosti aktera u komunikacijskoj mreži. Četvrti odjeljak premješta fokus s pojedinačnih čvorova na makrorazinu mrežne strukture, obrađujući gustoću, reciprocitet, tranzitivnost i raspodjele stupnjeva. Peti odjeljak bavi se detekcijom zajednica i klasterskom strukturom mreža, objašnjavajući kako se identificiraju grupe gusto povezanih aktera unutar šire mrežne strukture. Šesti odjeljak posvećen je vizualizaciji mreža kao analitičkom i komunikacijskom alatu, a poglavlje zaključuju razmatranja o metodološkim problemima i etičkim izazovima koji prate mrežna istraživanja u komunikologiji.
# Relacijska perspektiva
Zamislimo da želimo razumjeti tko je najutjecajnija osoba na hrvatskom Twitteru. Je li to korisnik s najviše pratitelja ili možda osoba čije objave redovito dijele novinari vodećih medijskih kuća? Ova naizgled jednostavna pitanja otkrivaju fundamentalnu promjenu u načinu na koji suvremena društvena znanost pristupa istraživanju masovne komunikacije. Umjesto da se analiziraju isključivo individualne karakteristike aktera, poput broja objava ili demografskih obilježja, fokus se premješta na proučavanje odnosa i veza među njima. Upravo taj pomak perspektive čini temelj analize društvenih mreža kao metodološkog pristupa. Ovaj pristup proizlazi iz spoznaje da društveni fenomeni nisu puki agregat individualnih atributa, već svojstva koja nastaju kroz interakciju. U kontekstu masovne komunikacije, to znači da razumijevanje širenja informacija, formiranja javnog mnijenja ili dinamike medijskog utjecaja zahtijeva mapiranje obrazaca povezanosti među akterima. Analiza društvenih mreža pruža teorijski okvir i metodološke alate za takvo istraživanje, omogućujući vizualizaciju, kvantifikaciju i interpretaciju strukture komunikacijskih tokova.
Tradicionalni pristupi u društvenim znanostima počivali su na pretpostavci da se ponašanje pojedinaca može objasniti proučavanjem njihovih atributa. U istraživanjima masovne komunikacije to se očitovalo kroz ankete koje mjere demografske varijable, stavove ili navike konzumacije medija. Takav pristup tretira pojedince kao izolirane jedinice čije karakteristike određuju njihovo ponašanje neovisno o društvenom kontekstu. Međutim, ova perspektiva zanemaruje činjenicu da su ljudi ukorijenjeni u mrežama odnosa koje oblikuju njihove stavove, ponašanja i mogućnosti djelovanja. **Relacijska perspektiva** predstavlja zaokret u znanstvenom mišljenju. Umjesto pitanja tko je netko, postavlja se pitanje s kim je povezan i na koji način. U kontekstu istraživanja medija, novinara ne definiraju samo njegove profesionalne kvalifikacije, već i mreža izvora, kolega i publike s kojima je povezan. Slično tome, viralnost sadržaja na društvenim mrežama ne ovisi isključivo o kvaliteti sadržaja, već o strukturnim pozicijama korisnika koji ga dijele. Upravo ta strukturna ukorijenjenost aktera čini središnji predmet analize društvenih mreža. Ovaj pomak od atributnog prema relacijskom pristupu konceptualno je srodan razlici između individualnih varijabli i kontekstualnih čimbenika u nacrtu istraživanja (v. poglavlje 3), gdje se također prepoznaje da ponašanje pojedinca ovisi o širem okruženju u kojem djeluje.
Razliku između atributnog i relacijskog pristupa moguće je ilustrirati jednostavnim primjerom iz prakse. Pretpostavimo da želimo identificirati ključne aktere u širenju dezinformacija na određenoj platformi. Atributni pristup fokusirao bi se na karakteristike pojedinih korisnika, poput učestalosti objavljivanja ili duljine članstva na platformi. S druge strane, relacijski pristup mapirao bi obrasce dijeljenja sadržaja među korisnicima, identificirajući čvorišta kroz koja informacije protječu i mostove koji povezuju različite zajednice. Ovaj drugi pristup omogućuje razumijevanje sistemske dinamike širenja informacija, otkrivajući strukturne ranjivosti informacijskog ekosustava. Prije nego što se razmotre specifične metode analize, potrebno je precizno definirati temeljne elemente od kojih se svaka mreža sastoji.
## Čvorovi i veze
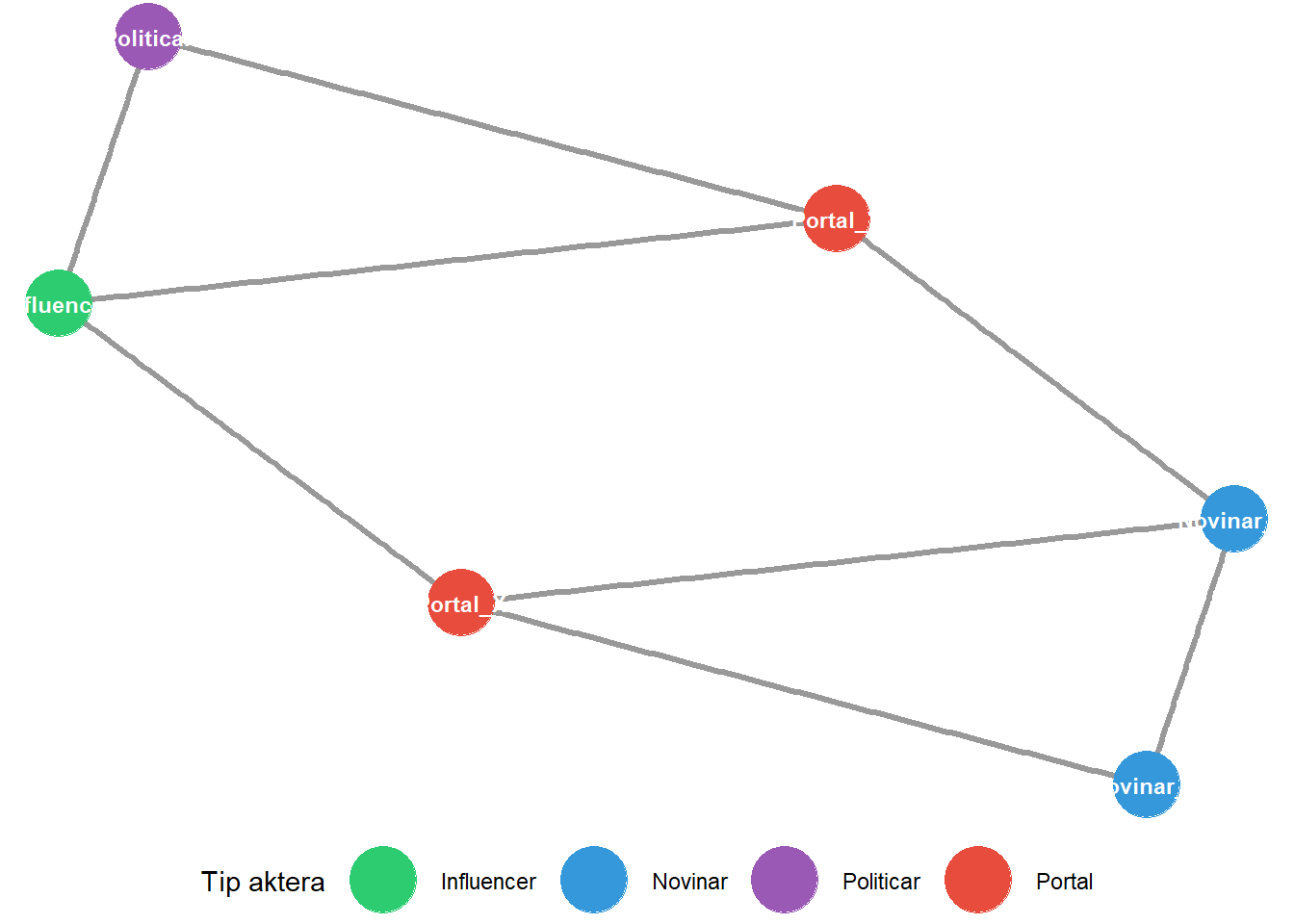
Svaka mreža sastoji se od dva temeljna elementa. Prvi element jesu **čvorovi** koji predstavljaju entitete od interesa u istraživanju. U teoriji grafova koristi se i termin vrhovi, dok u sociološkoj tradiciji govorimo o akterima. U kontekstu istraživanja masovne komunikacije, čvorovi mogu predstavljati novinare, medijske kuće, političare, influencere ili obične korisnike društvenih mreža. Izbor entiteta koje ćemo modelirati kao čvorove ovisi o istraživačkom pitanju i teorijskom okviru studije. Drugi temeljni element mreže jesu **veze** koje povezuju čvorove. U literaturi se koriste i termini bridovi ili relacije. Veze predstavljaju odnose među akterima i mogu poprimiti različite oblike ovisno o fenomenu koji proučavamo. Primjerice, veza može predstavljati dijeljenje objave na društvenoj mreži, citiranje izvora u novinarskom članku, hiperlinkove između web stranica ili vlasničke strukture među medijskim kućama. Priroda veze određuje interpretaciju mrežne strukture, stoga je precizna definicija relacije od presudne važnosti za valjanost istraživanja. Operacionalizacija čvorova i veza u mrežnoj analizi analogna je operacionalizaciji varijabli u klasičnom istraživačkom nacrtu (v. poglavlje 3), pri čemu istraživač mora jasno definirati što čini jedinicu analize i kako se mjeri odnos među jedinicama.
```{r}
#| label: fig-basic-network
#| fig-cap: "Osnovni elementi mreže: čvorovi (prikazani krugovima) i veze (prikazane linijama) čine temeljnu strukturu svake mrežne analize."
#| fig-width: 7
#| fig-height: 5
set.seed(42)
# Definiranje veza među akterima pomoću funkcije graph_from_literal()
basic_net <- graph_from_literal(
Novinar_A -- Novinar_B,
Novinar_A -- Portal_X,
Novinar_B -- Portal_X,
Novinar_B -- Portal_Y,
Portal_X -- Influencer,
Portal_Y -- Influencer,
Portal_Y -- Politicar,
Influencer -- Politicar
)
# Dodjela tipova aktera za vizualno razlikovanje
V(basic_net)$type <- c("Novinar", "Novinar", "Portal", "Portal", "Influencer", "Politicar")
V(basic_net)$color <- case_when(
V(basic_net)$type == "Novinar" ~ "#3498db",
V(basic_net)$type == "Portal" ~ "#e74c3c",
V(basic_net)$type == "Influencer" ~ "#2ecc71",
V(basic_net)$type == "Politicar" ~ "#9b59b6"
)
# Pretvaranje u tidy format za vizualizaciju pomoću ggraph
basic_tidy <- as_tbl_graph(basic_net)
# Vizualizacija mreže
ggraph(basic_tidy, layout = "fr") +
geom_edge_link(color = "gray60", width = 1.2) +
geom_node_point(aes(color = type), size = 12) +
geom_node_text(aes(label = name), size = 3, color = "white", fontface = "bold") +
scale_color_manual(
values = c("Novinar" = "#3498db", "Portal" = "#e74c3c",
"Influencer" = "#2ecc71", "Politicar" = "#9b59b6"),
name = "Tip aktera"
) +
theme_void() +
theme(legend.position = "bottom")
```
U prikazanom primjeru mreža je kreirana pomoću funkcije `graph_from_literal()` iz paketa `igraph`, koja omogućuje intuitivno definiranje veza korištenjem operatora `--`, a vizualizirana je pomoću paketa `ggraph` koji mrežne podatke prikazuje u skladu s gramatikom grafike poznata iz `ggplot2` sustava. Formalno, mrežu je moguće definirati kao uređeni par G = (V, E), gdje V predstavlja skup čvorova, a E skup veza među njima. Svaka veza e iz skupa E definirana je kao par čvorova (v1, v2) koje povezuje. Jednostavnije rečeno, mreža se sastoji od popisa svih aktera i popisa svih veza među njima, pri čemu se za svaku vezu bilježi koji su akteri njome povezani. Ova matematička formalizacija omogućuje precizno opisivanje strukture mreže i primjenu algoritama za njezinu analizu. Nadalje, čvorovi i veze mogu imati pridružene atribute koji obogaćuju analizu. Primjerice, čvorovima mogu biti pridruženi podaci o geografskoj lokaciji ili broju pratitelja, dok veze mogu nositi informaciju o vremenu nastanka ili učestalosti interakcije. U istraživanjima masovne komunikacije, akter može biti bilo koji entitet koji sudjeluje u komunikacijskom procesu. Medijska kuća poput HRT-a, portal Index.hr, novinar s imenom i prezimenom, ali i anonimni korisnik Twittera koji dijeli vijesti, svi oni mogu biti modelirani kao čvorovi u komunikacijskoj mreži. Ključno je razumjeti da mreža nije objektivna stvarnost, već analitička konstrukcija koju istraživač gradi prema svojim teorijskim pretpostavkama i istraživačkim ciljevima.
Nakon definiranja temeljnih elemenata mrežne analize, korisno je razmotriti kako se ovaj pristup razvijao kroz povijest, jer povijesni kontekst pomaže razumjeti podrijetlo suvremenih koncepata i terminologije.
## Povijesni razvoj
Korijeni analize društvenih mreža sežu u tridesete godine dvadesetog stoljeća i rad rumunjsko-američkog psihijatra **Jacoba Levy Morena**. Moreno je razvio **sociometriju** kao metodu za proučavanje interpersonalnih odnosa unutar grupa. Njegova ključna inovacija bila je **sociogram**, grafički prikaz društvenih odnosa u kojem su pojedinci predstavljeni točkama, a njihovi odnosi linijama koje ih povezuju. U svojoj knjizi objavljenoj 1934. godine, Moreno je primijenio sociometrijske metode za analizu društvene strukture u institucijama poput škola i zatvora. Time je postavio temelje za sustavno empirijsko proučavanje mrežnih obrazaca. Morenov pristup donio je revolucionarnu spoznaju da prije bilo kakvog društvenog programa istraživač mora uzeti u obzir stvarnu konstituciju grupe. Sociometrija je omogućila otkrivanje skrivenih struktura koje oblikuju grupu, uključujući saveze, podgrupe, neizrečena uvjerenja i zabranjene agende. Moreno je identificirao konfiguraciju koju je nazvao sociometrijskom zvijezdom, odnosno pojedinca kojeg mnogi drugi biraju kao prijatelja. Ti rani uvidi anticipirali su suvremene koncepte poput čvorišta (engl. *hubs*) i utjecajnih korisnika u digitalnim mrežama.
Sljedeći prijelomni trenutak u razvoju mrežnog pristupa predstavlja eksperiment **Stanleyja Milgrama** iz 1967. godine, poznat kao eksperiment malog svijeta. Milgram je postavio jednostavno pitanje koliko posrednika treba da poveže dva nasumično odabrana čovjeka u Sjedinjenim Američkim Državama? Koristeći metodu lančanih pisama, Milgram je otkrio da je prosječna udaljenost između ispitanika iz Nebraske i ciljne osobe u Bostonu iznosila samo pet do šest koraka. Ovaj nalaz populariziran je pod nazivom **šest stupnjeva odvojenosti**, iako sam Milgram taj termin nikada nije upotrijebio. Milgramov eksperiment imao je duboke implikacije za razumijevanje društvene strukture. Otkrio je da bez obzira na ogromnu veličinu populacije, ljudsko društvo karakteriziraju iznenađujuće kratki lanci poznanstava. Nadalje, eksperiment je pokazao da se polovica svih pisama koja su stigla do cilja prošla kroz samo tri osobe, sugerirajući postojanje ključnih posrednika u društvenoj mreži. Ovi posrednici, koje suvremena mrežna znanost naziva mostovima ili povezivačima, igraju neproporcionalnu ulogu u širenju informacija kroz društvo.
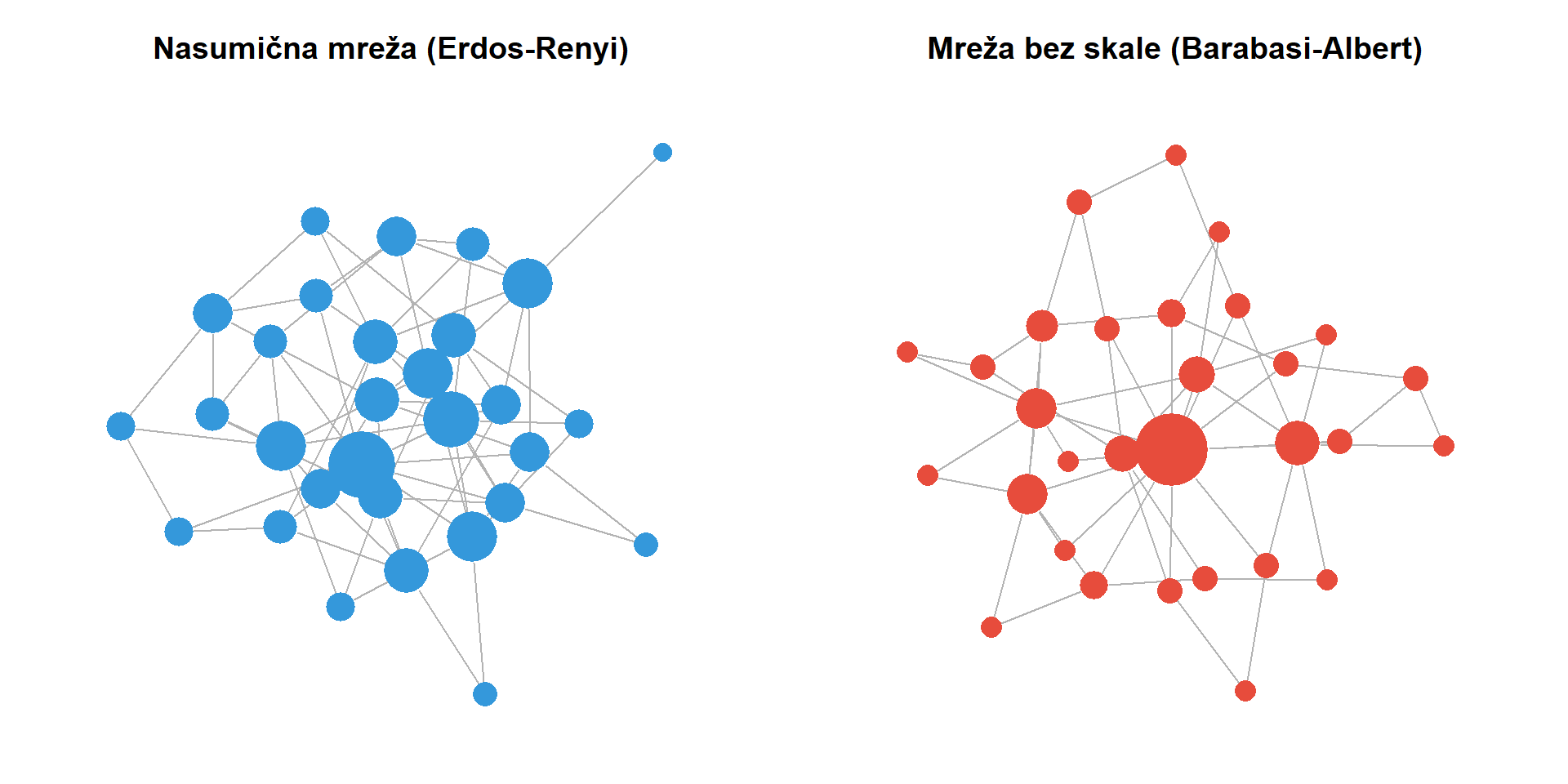
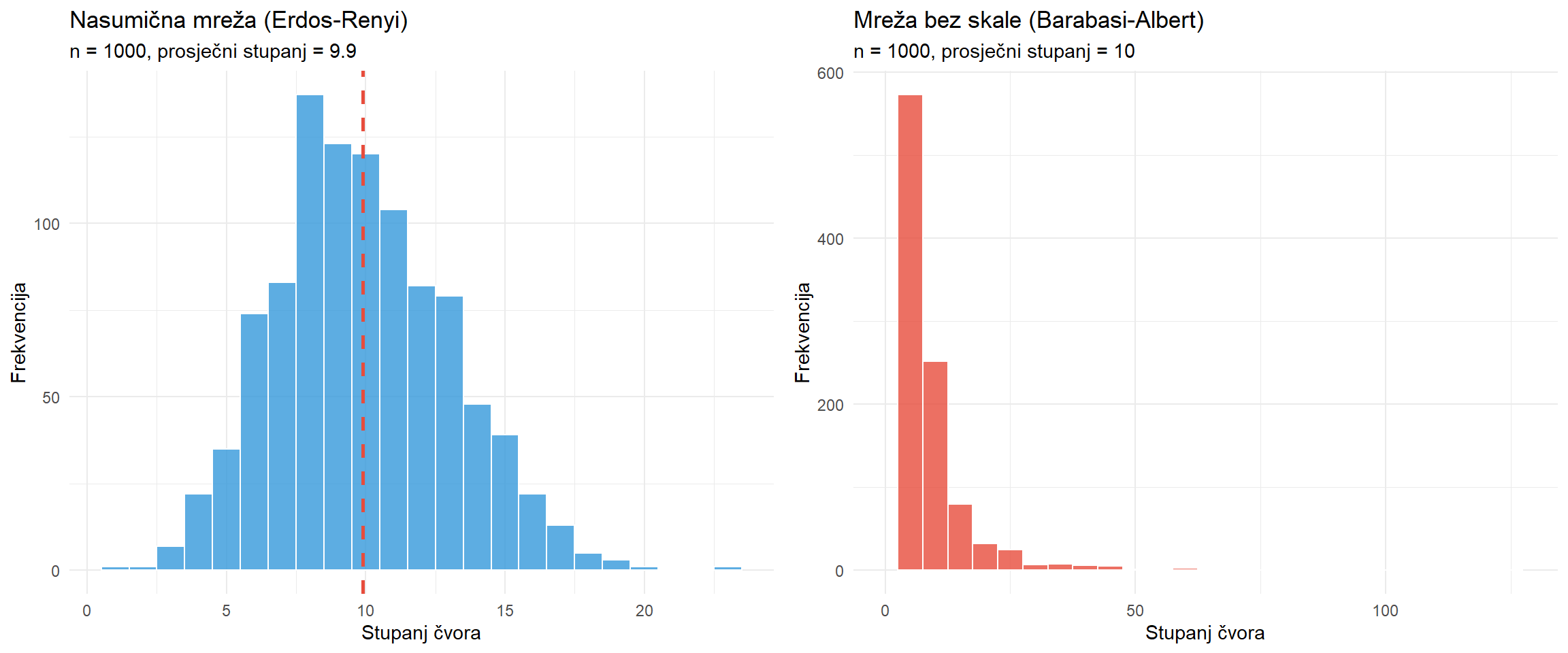
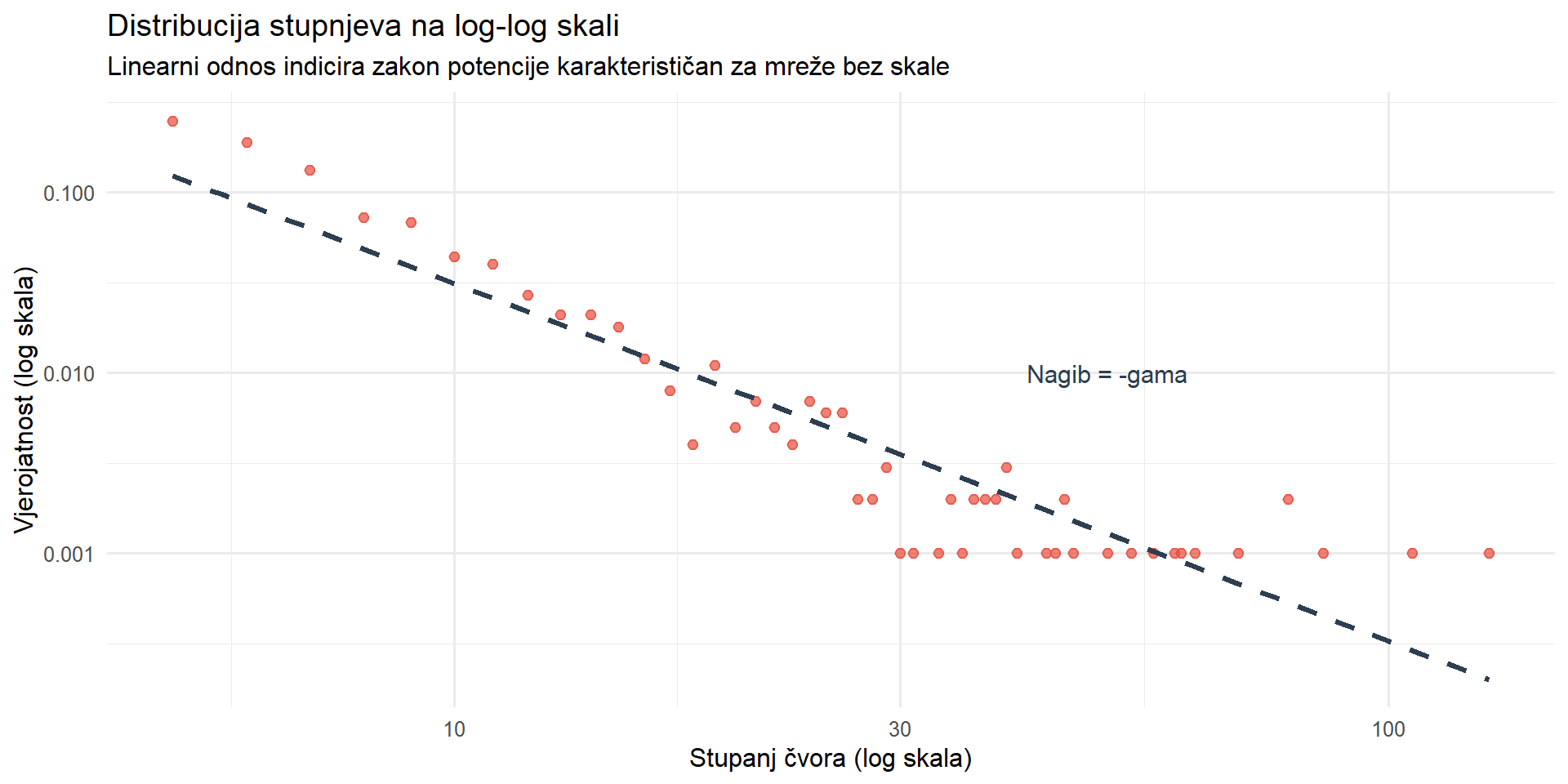
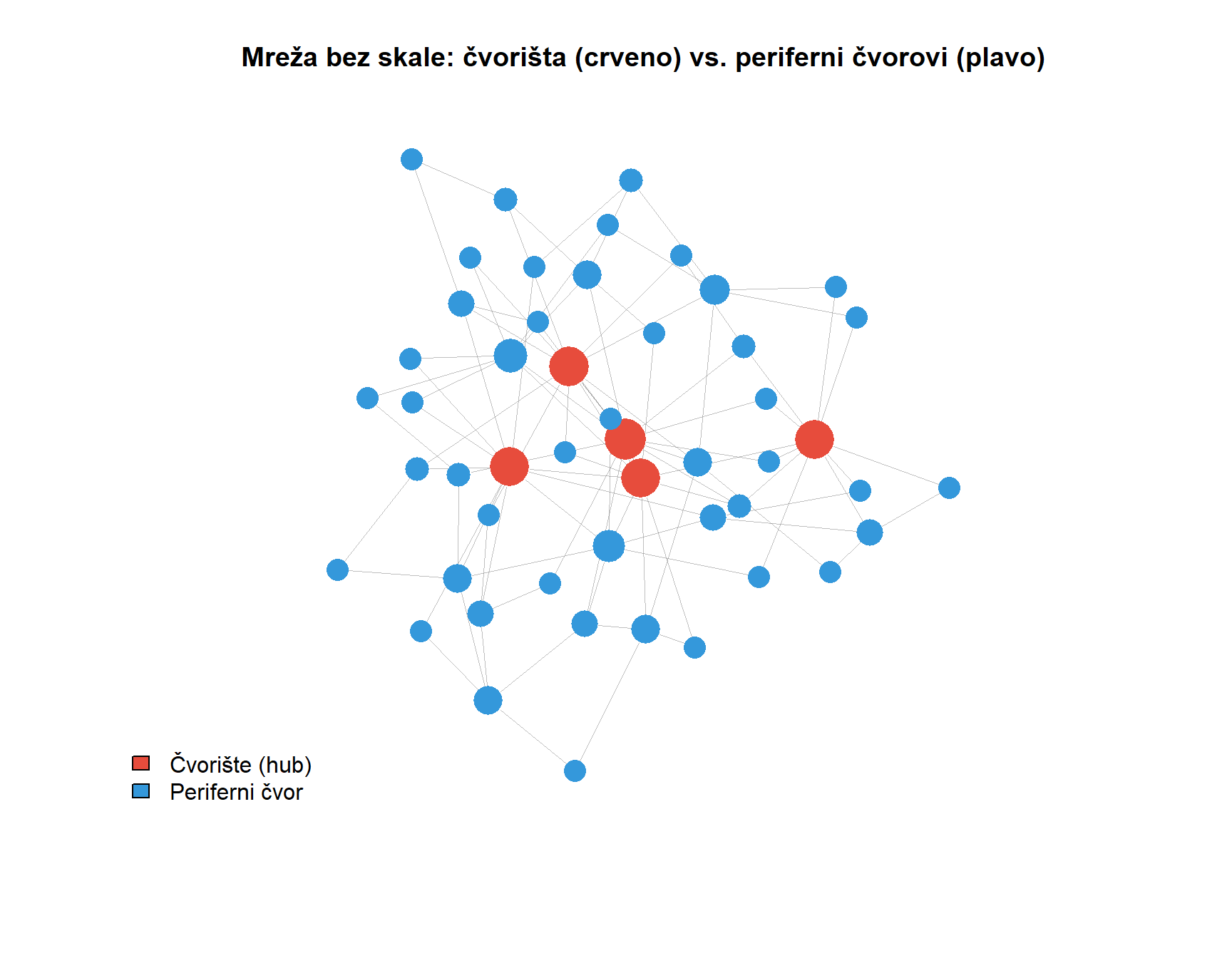
Suvremena era mrežne znanosti započinje krajem devedesetih godina dvadesetog stoljeća radom **Alberta-Laszla Barabasija** i njegove suradnice Reke Albert. Analizirajući topologiju dijela World Wide Weba, Barabasi je otkrio da distribucija povezanosti stranica ne slijedi normalnu raspodjelu koja bi se očekivala u nasumičnim mrežama. Umjesto toga, distribucija je slijedila zakon potencije, što znači da mali broj stranica ima ogroman broj dolaznih veza dok velika većina stranica ima vrlo malo veza. Ovu strukturu Barabasi je nazvao **mrežom bez skale**, a objasnio ju je mehanizmom **preferencijskog prikapčanja**. Prema ovom mehanizmu, novi čvorovi koji ulaze u mrežu imaju veću vjerojatnost povezivanja s već dobro povezanim čvorovima. Intuitivno, ovo se može razumjeti kao fenomen bogatiji postaju bogatiji. Nova web stranica vjerojatnije će postaviti hiperveze prema Googleu nego prema nepoznatom blogu, baš kao što novi korisnik Twittera vjerojatnije slijedi poznatu javnu osobu nego anonimnog korisnika.
```{r}
#| label: fig-scale-free
#| fig-cap: "Usporedba nasumične mreže (lijevo) i mreže bez skale (desno). U mreži bez skale jasno su vidljiva čvorišta s velikim brojem veza, dok nasumična mreža pokazuje ujednačeniju distribuciju povezanosti."
#| fig-width: 10
#| fig-height: 5
set.seed(123)
# Generiranje nasumične mreže prema Erdos-Renyi modelu
random_net <- erdos.renyi.game(30, 0.15, type = "gnp")
# Generiranje mreže bez skale prema Barabasi-Albert modelu
scale_free_net <- barabasi.game(30, m = 2, directed = FALSE)
par(mfrow = c(1, 2), mar = c(1, 1, 3, 1))
# Veličina čvora proporcionalna stupnju (broju veza)
V(random_net)$size <- degree(random_net) * 2 + 5
V(random_net)$color <- "#3498db"
plot(random_net,
vertex.label = NA,
edge.color = "gray70",
main = "Nasumična mreža (Erdos-Renyi)",
vertex.frame.color = NA)
V(scale_free_net)$size <- degree(scale_free_net) * 1.5 + 5
V(scale_free_net)$color <- "#e74c3c"
plot(scale_free_net,
vertex.label = NA,
edge.color = "gray70",
main = "Mreža bez skale (Barabasi-Albert)",
vertex.frame.color = NA)
```
Barabasijevo otkriće imalo je dalekosežne implikacije za razumijevanje komunikacijskih sustava. Mreže bez skale karakterizira postojanje **čvorišta** (engl. *hubs*), odnosno čvorova s disproporcionalno velikim brojem veza. U kontekstu masovne komunikacije, čvorišta mogu biti mainstream mediji čije sadržaje preuzimaju deseci manjih portala, ili influenceri čije objave dijele tisuće pratitelja. Razumijevanje uloge čvorišta ključno je za analizu procesa poput širenja vijesti, formiranja javnog mnijenja ili dinamike dezinformacijskih kampanja. U R-u se nasumične mreže generiraju funkcijom `erdos.renyi.game()`, a mreže bez skale funkcijom `barabasi.game()`, obje iz paketa `igraph`, što omogućuje eksperimentiranje s različitim mrežnim topologijama i usporedbu njihovih svojstava. Razumijevanje ovih povijesnih temelja pruža kontekst za formalniju klasifikaciju mrežnih struktura koja slijedi u nastavku.
# Osnovni elementi i vrste mreža
Razumijevanje različitih tipova mrežnih struktura preduvjet je za odabir odgovarajućih analitičkih metoda i ispravnu interpretaciju rezultata. Mreže se mogu klasificirati prema nekoliko ključnih dimenzija koje odražavaju prirodu odnosa koji se proučavaju. U ovom odjeljku razmatraju se tri temeljne karakteristike mrežnih podataka: usmjerenost veza, njihova težina te načini formalnog prikaza mrežne strukture.
## Usmjerenost veza
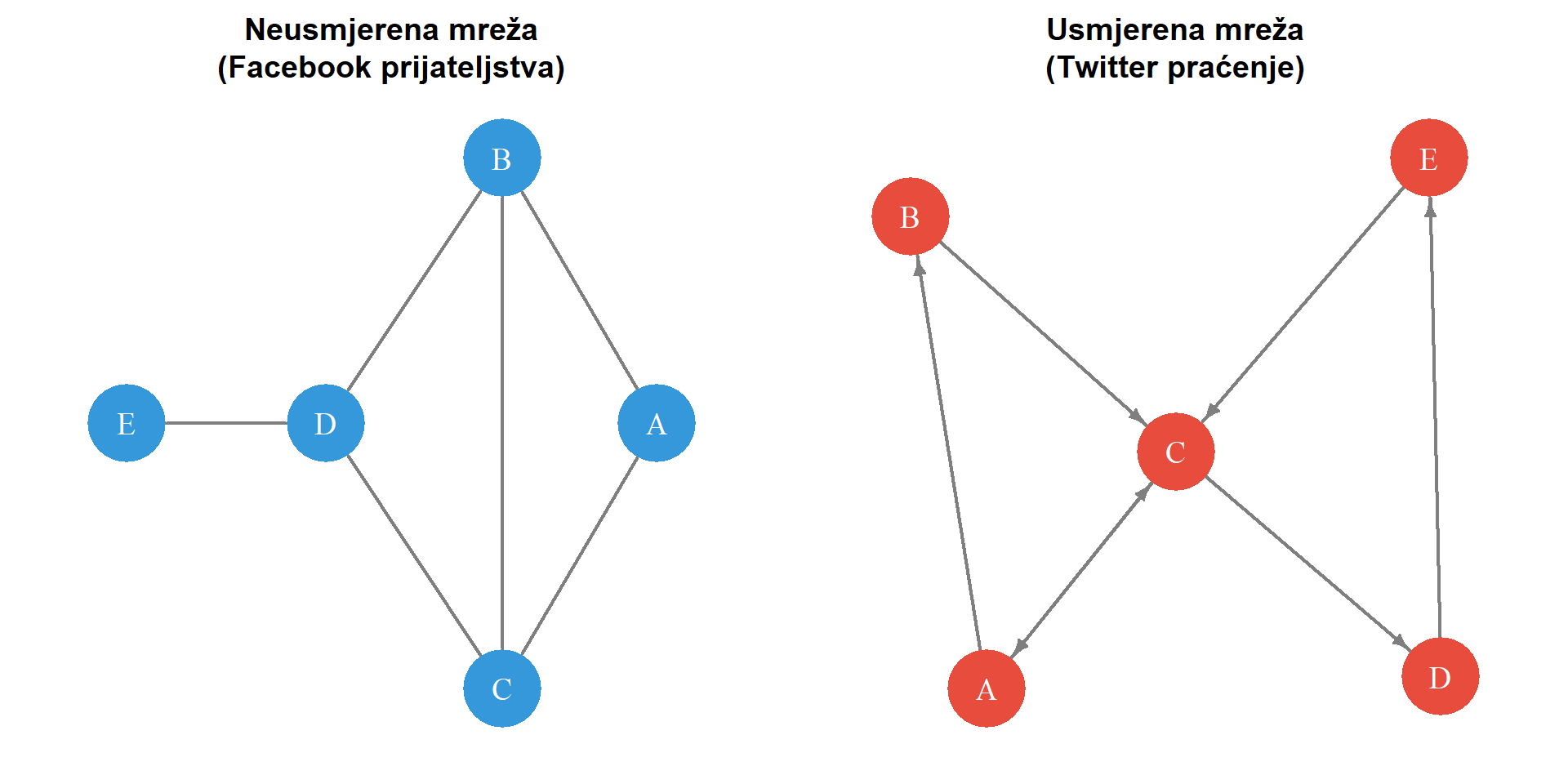
Jedna od temeljnih distinkcija u mrežnoj analizi jest razlika između **usmjerenih** i **neusmjerenih mreža**. U neusmjerenoj mreži veze nemaju smjer, što znači da ako postoji veza između čvora A i čvora B, ona je simetrična. Primjer neusmjerene mreže bio bi sustav komunikacije u kojem mjerimo jesu li dvije osobe međusobni prijatelji na Facebooku. U tom slučaju, prijateljstvo je po definiciji obostrano jer obje strane moraju prihvatiti zahtjev za prijateljstvom. S druge strane, **usmjerene mreže** karakterizira asimetričnost odnosa. Veza ima definiran smjer koji ide od izvornog čvora prema ciljnom čvoru. Klasičan primjer usmjerene mreže jest praćenje na Twitteru ili Instagramu, gdje korisnik A može pratiti korisnika B bez da korisnik B uzvraća praćenje. U kontekstu istraživanja medija, usmjerene mreže često modeliraju tokove informacija. Primjerice, mreža citiranja članaka usmjerena je jer članak A može citirati članak B, a da pritom članak B ne citira članak A.
```{r}
#| label: fig-directed-undirected
#| fig-cap: "Usporedba neusmjerene mreže (lijevo) gdje su veze simetrične i usmjerene mreže (desno) gdje strelice pokazuju smjer odnosa. U kontekstu društvenih mreža, neusmjerena mreža mogla bi predstavljati Facebook prijateljstva, dok usmjerena predstavlja Twitter praćenje."
#| fig-width: 10
#| fig-height: 5
set.seed(42)
# Definiranje bridova za neusmjerenu mrežu
edges_undir <- data.frame(
from = c("A", "A", "B", "B", "C", "D"),
to = c("B", "C", "C", "D", "D", "E")
)
undirected_net <- graph_from_data_frame(edges_undir, directed = FALSE)
# Definiranje bridova za usmjerenu mrežu
edges_dir <- data.frame(
from = c("A", "A", "B", "C", "C", "D", "E"),
to = c("B", "C", "C", "D", "A", "E", "C")
)
directed_net <- graph_from_data_frame(edges_dir, directed = TRUE)
par(mfrow = c(1, 2), mar = c(1, 1, 3, 1))
# Vizualizacija neusmjerene mreže
plot(undirected_net,
vertex.size = 30,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray50",
edge.width = 2,
main = "Neusmjerena mreža\n(Facebook prijateljstva)")
# Vizualizacija usmjerene mreže sa strelicama
plot(directed_net,
vertex.size = 30,
vertex.color = "#e74c3c",
vertex.frame.color = NA,
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray50",
edge.width = 2,
edge.arrow.size = 0.6,
main = "Usmjerena mreža\n(Twitter praćenje)")
```
Razlikovanje usmjerenih i neusmjerenih mreža ima značajne analitičke implikacije. U usmjerenim mrežama razlikujemo **ulazni stupanj** koji mjeri broj veza koje dolaze u čvor, te **izlazni stupanj** koji mjeri broj veza koje izlaze iz čvora. U kontekstu Twittera, ulazni stupanj odgovara broju pratitelja, dok izlazni stupanj odgovara broju računa koje korisnik prati. Ova distinkcija omogućuje identificiranje različitih tipova aktera. Korisnik s visokim ulaznim stupnjem i niskim izlaznim stupnjem mogao bi biti influencer kojeg mnogi prate, ali on prati malo drugih. Obratno, korisnik s visokim izlaznim stupnjem i niskim ulaznim stupnjem mogao bi biti netko tko aktivno prati novosti, ali sam nije popularan. U istraživanjima masovne komunikacije, izbor između usmjerene i neusmjerene mreže ovisi o prirodi fenomena koji se proučava. Ako je u fokusu pitanje tko utječe na koga, usmjerena mreža pružit će bogatije informacije. Međutim, ako se proučava suradnja ili zajednička pripadnost grupama, neusmjerena mreža može biti primjereniji izbor. Primjerice, mreža koautorstva znanstvenih radova tipično se modelira kao neusmjerena jer koautorstvo podrazumijeva obostrani odnos. U R-u se neusmjerena mreža kreira pozivom `graph_from_data_frame(edges, directed = FALSE)`, dok se usmjerena kreira s argumentom `directed = TRUE`. Uz usmjerenost, druga bitna dimenzija koja određuje karakter mrežnih podataka jest intenzitet odnosa među čvorovima.
## Težina veze
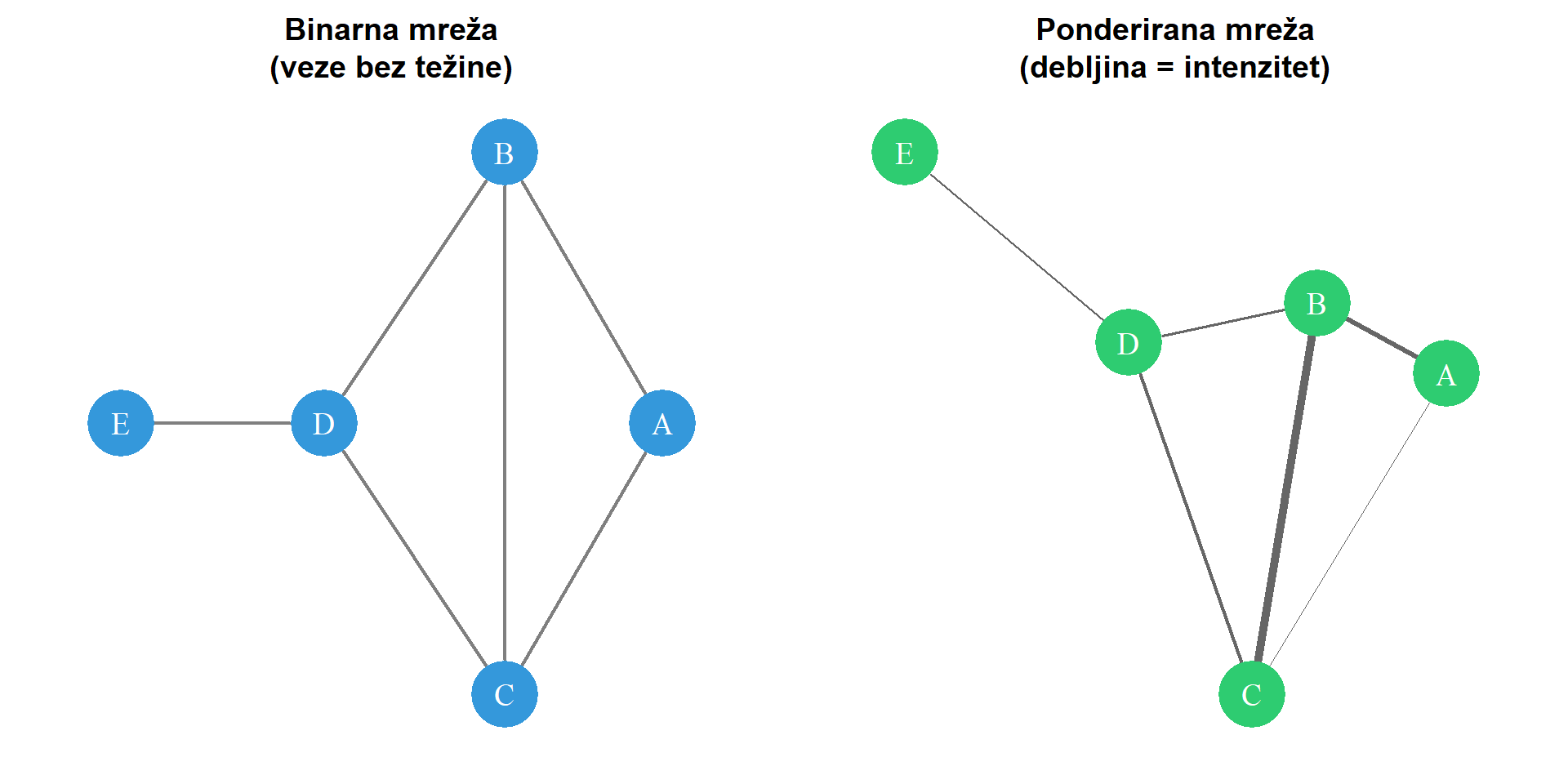
Druga važna dimenzija mrežne strukture jest razlika između **binarnih** i **ponderiranih mreža**. U binarnoj mreži veza između dva čvora može samo postojati ili ne postojati. Formalno, težina svake veze iznosi ili jedan ili nula. Ovakav prikaz pojednostavljuje strukturu mreže, ali gubi informaciju o intenzitetu odnosa. Primjerice, binarna mreža dijeljenja sadržaja bilježi samo činjenicu da je korisnik A podijelio objavu korisnika B, ne uzimajući u obzir koliko je puta to učinio. Nasuprot tome, **ponderirane mreže** svakoj vezi pridružuju numeričku vrijednost koja odražava snagu ili intenzitet odnosa. Ova težina može predstavljati učestalost interakcije, trajanje veze, količinu razmijenjenih resursa ili neku drugu mjeru jačine odnosa. U istraživanjima komunikacije, težina veze mogla bi predstavljati broj zajedničkih članaka koje su dva novinara napisala, učestalost međusobnih retvitova ili količinu prometa između dvije web stranice.
```{r}
#| label: fig-weighted
#| fig-cap: "Usporedba binarne mreže (lijevo) gdje sve veze imaju jednaku težinu i ponderirane mreže (desno) gdje debljina linije označava intenzitet odnosa. U ponderiranoj mreži vidljivo je da neke veze predstavljaju snažnije odnose od drugih."
#| fig-width: 10
#| fig-height: 5
set.seed(42)
# Binarna mreža: sve veze imaju jednaku težinu
edges_binary <- data.frame(
from = c("Portal_A", "Portal_A", "Portal_B", "Portal_B", "Portal_C", "Portal_D"),
to = c("Portal_B", "Portal_C", "Portal_C", "Portal_D", "Portal_D", "Portal_E")
)
binary_net <- graph_from_data_frame(edges_binary, directed = FALSE)
# Ponderirana mreža: svaka veza ima pridruženu težinu
edges_weighted <- data.frame(
from = c("Portal_A", "Portal_A", "Portal_B", "Portal_B", "Portal_C", "Portal_D"),
to = c("Portal_B", "Portal_C", "Portal_C", "Portal_D", "Portal_D", "Portal_E"),
weight = c(15, 3, 25, 8, 12, 5)
)
weighted_net <- graph_from_data_frame(edges_weighted, directed = FALSE)
par(mfrow = c(1, 2), mar = c(1, 1, 3, 1))
# Vizualizacija binarne mreže
plot(binary_net,
vertex.size = 25,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = c("A", "B", "C", "D", "E"),
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray50",
edge.width = 2,
main = "Binarna mreža\n(veze bez težine)")
# Vizualizacija ponderirane mreže: debljina linije odražava težinu
plot(weighted_net,
vertex.size = 25,
vertex.color = "#2ecc71",
vertex.frame.color = NA,
vertex.label = c("A", "B", "C", "D", "E"),
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray40",
edge.width = E(weighted_net)$weight / 5,
main = "Ponderirana mreža\n(debljina = intenzitet)")
```
Prednost ponderiranih mreža leži u njihovoj informativnosti. Veza između dva čvora koja se ostvaruje jednom tjedno kvalitativno je različita od veze koja se ostvaruje svakodnevno, premda obje postoje u binarnom smislu. Ponderirana mreža hvata tu razliku i omogućuje sofisticiranije analize. S druge strane, prikupljanje podataka o težini veza može biti zahtjevnije, a određene analitičke metode razvijene su primarno za binarne mreže. Istraživač mora pažljivo odvagnuti prednosti i nedostatke svakog pristupa s obzirom na istraživačka pitanja i dostupne podatke. U praksi se ponekad ponderirane mreže pretvaraju u binarne primjenom praga. Definira se vrijednost ispod koje se smatra da veza ne postoji. Primjerice, moguće je odlučiti da veza među korisnicima postoji samo ako su razmijenili najmanje pet poruka. Ovaj postupak **binarizacije** pojednostavljuje analizu, ali izbor praga utječe na rezultate i mora biti teorijski opravdan. Bez obzira na to jesu li veze usmjerene ili neusmjerene, binarne ili ponderirane, svaku je mrežu potrebno prikazati u formaliziranom obliku pogodnom za računalnu obradu i analizu.
## Matrični prikaz mreže
Za analitičke svrhe, mrežne strukture mogu se prikazati u različitim formatima podataka. Najčešći i najsvestraniji format jest **matrica susjedstva** (*adjacency matrix*). Ova kvadratna matrica dimenzija n x n, gdje n predstavlja broj čvorova u mreži, bilježi postojanje i eventualnu težinu veza među svim parovima čvorova. U matrici susjedstva retci i stupci označeni su imenima ili identifikatorima čvorova. Vrijednost u ćeliji na presjeku retka i i stupca j označava vezu od čvora i prema čvoru j. U binarnoj mreži, vrijednost jedan označava postojanje veze, dok vrijednost nula označava njezinu odsutnost. U ponderiranoj mreži, vrijednost u ćeliji odgovara težini veze. Dijagonala matrice predstavlja potencijalne samopoveznice, odnosno veze čvora sa samim sobom, koje se u mnogim primjenama postavljaju na nulu.
```{r}
#| label: tbl-adjacency
#| tbl-cap: "Primjer matrice susjedstva za hipotetsku mrežu citiranja među četiri medijske kuće. Vrijednosti označavaju broj citiranja tijekom jednomjesečnog razdoblja."
# Kreiranje matrice susjedstva s podatcima o citiranju
adj_matrix <- data.frame(
Medij = c("HRT", "N1", "Index", "Jutarnji"),
HRT = c(0, 2, 0, 1),
N1 = c(3, 0, 2, 0),
Index = c(1, 4, 0, 3),
Jutarnji = c(2, 1, 5, 0)
)
kable(adj_matrix, align = c("l", rep("c", 4))) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = FALSE)
```
Iz gornje tablice moguće je iščitati obrasce citiranja među medijima. Primjerice, vrijednost 3 u ćeliji HRT-N1 označava da je HRT citirao N1 tri puta. Uočava se da matrica nije simetrična jer je riječ o usmjerenoj mreži. Index je citirao Jutarnji pet puta, dok je Jutarnji citirao Index tri puta. Ova asimetrija pruža uvid u tokove informacija i potencijalnu hijerarhiju izvora među medijima.
Za neusmjerene mreže, matrica susjedstva je simetrična, što znači da je vrijednost u ćeliji (i, j) jednaka vrijednosti u ćeliji (j, i). Ova simetrija proizlazi iz činjenice da u neusmjerenoj mreži veza između A i B podrazumijeva i vezu između B i A. Nasuprot tome, u usmjerenim mrežama poput one prikazane u tablici, matrica općenito nije simetrična jer veza od A prema B ne implicira vezu od B prema A. U R-u se mrežni objekt iz matrice susjedstva kreira funkcijom `graph_from_adjacency_matrix()` iz paketa `igraph`, dok se mreža iz tablice bridova kreira funkcijom `graph_from_data_frame()`. Ovi su formati izravno prenosivi, tj. isti mrežni objekt može se zapisati i kao matrica i kao lista bridova ovisno o potrebama analize.
Osim matrice susjedstva, mrežni podaci mogu se prikazati i u obliku **liste bridova**. Ovaj format jednostavno nabraja sve postojeće veze u mreži, navodeći za svaku vezu izvorni i ciljni čvor te eventualnu težinu. Lista bridova prostorno je učinkovitija od matrice susjedstva za rijetke mreže u kojima većina potencijalnih veza ne postoji. Primjerice, u velikoj mreži s milijun čvorova, matrica susjedstva imala bi bilijun ćelija od kojih bi većina sadržavala nule. Lista bridova bilježila bi samo postojeće veze, značajno smanjujući memorijske zahtjeve.
```{r}
#| label: tbl-formats
#| tbl-cap: "Usporedba formata mrežnih podataka s njihovim prednostima i nedostacima."
# Usporedna tablica triju najčešćih formata za pohranu mrežnih podataka
formats_df <- data.frame(
Format = c("Matrica susjedstva", "Lista bridova", "Lista susjedstva"),
Struktura = c("Kvadratna matrica n x n", "Parovi čvorova s težinama", "Za svaki čvor popis susjeda"),
Prednosti = c("Omogućuje matrične operacije, intuitivna", "Memorijski učinkovita, jednostavna", "Brz pristup susjedima"),
Nedostaci = c("Neučinkovita za rijetke mreže", "Manje pogodna za neke algoritme", "Složenija struktura podataka")
)
kable(formats_df) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Iz usporedbe je vidljivo da izbor formata ovisi o veličini i gustoći mreže: za male, guste mreže matrica susjedstva je intuitivnija i omogućuje izravnu primjenu matričnih operacija, dok je za velike, rijetke mreže lista bridova memorijski znatno učinkovitija. Razumijevanje ovih temeljnih koncepata i formata podataka preduvjet je za daljnje proučavanje mrežnih metrika i analitičkih postupaka. U sljedećem odjeljku razmatraju se mjere centralnosti koje omogućuju identificiranje ključnih aktera u mreži, strukturne karakteristike poput gustoće i klasteriranja koje opisuju mrežu na agregatnoj razini, te metode za detekciju zajednica i analizu difuzijskih procesa.
# Mjere centralnosti
Zamislimo istraživača koji proučava mrežu dijeljenja političkih vijesti na hrvatskom Twitteru tijekom izborne kampanje. Pred sobom ima mrežu s tisućama korisnika i desecima tisuća veza koje predstavljaju retvitove. Središnje pitanje koje si postavlja jest: tko su najvažniji akteri u ovoj mreži? Intuitivno, važnost se čini jednostavnim konceptom, no dubljom analizom postaje jasno da postoje različiti načini na koje čvor može biti važan. Korisnik s najviše pratitelja važan je po jednom kriteriju, korisnik čije objave povezuju ideološki različite skupine važan je po drugom, a korisnik čije objave najbrže dosežu cijelu mrežu važan je po trećem. Mjere centralnosti formaliziraju ove različite intuicije o važnosti, pružajući kvantitativne alate za identificiranje ključnih aktera u mrežnim strukturama.
**Centralnost** u analizi mreža odnosi se na skup metrika koje kvantificiraju relativnu važnost ili istaknutost čvorova unutar mrežne strukture. Različite mjere centralnosti operacionaliziraju različite koncepte važnosti, a izbor odgovarajuće mjere ovisi o teorijskom pitanju koje istraživač postavlja i o karakteristikama fenomena koji proučava. U kontekstu istraživanja masovne komunikacije, mjere centralnosti omogućuju identificiranje utjecajnih medija, ključnih novinara, gatekeepera informacija i mostova između različitih zajednica. Svaka mjera centralnosti odgovara na specifično pitanje o ulozi čvora u mreži, stoga je razumijevanje logike različitih mjera preduvjet za njihovu ispravnu primjenu i interpretaciju.
```{r}
#| label: create-example-network
#| include: false
# Kreiranje hipotetske mreže hrvatskih medija za ilustraciju mjera centralnosti
set.seed(42)
media_edges <- data.frame(
from = c("HRT", "HRT", "HRT", "N1", "N1", "N1", "N1", "Index", "Index",
"Index", "Jutarnji", "Jutarnji", "Vecernji", "Vecernji",
"Portal_A", "Portal_A", "Portal_B", "Blog_X", "Blog_Y", "Blog_Y"),
to = c("N1", "Index", "Jutarnji", "Index", "Vecernji", "Portal_A", "Blog_X",
"Jutarnji", "Vecernji", "Portal_B", "Vecernji", "Portal_A",
"Portal_A", "Portal_B", "Portal_B", "Blog_X", "Blog_Y", "Blog_Y", "HRT", "N1")
)
# Kreiranje mrežnog objekta i dodjela tipova aktera
media_net <- graph_from_data_frame(media_edges, directed = FALSE)
V(media_net)$type <- case_when(
V(media_net)$name %in% c("HRT", "N1") ~ "Javni medij",
V(media_net)$name %in% c("Index", "Jutarnji", "Vecernji") ~ "Komercijalni portal",
V(media_net)$name %in% c("Portal_A", "Portal_B") ~ "Manji portal",
TRUE ~ "Blog"
)
```
## Stupanj centralnosti
Najjednostavnija i najintuitivnija mjera centralnosti jest **stupanj centralnosti** (engl. *degree centrality*) koja mjeri broj izravnih veza koje čvor ima s drugim čvorovima u mreži. Logika ove mjere proizlazi iz pretpostavke da čvorovi s više veza imaju više mogućnosti za interakciju, utjecaj i pristup resursima koji cirkuliraju mrežom. U kontekstu društvenih mreža, osoba s više prijatelja ili poznanika ima veći socijalni kapital, više izvora informacija i potencijalno veći utjecaj na svoje okruženje.
Formalno, stupanj centralnosti čvora $i$ u neusmjerenoj mreži definira se jednostavno kao broj bridova incidentnih na taj čvor:
$$C_D(i) = k_i = \sum_{j} a_{ij}$$
U ovoj formuli $k_i$ označava stupanj čvora $i$, a $a_{ij}$ je element matrice susjedstva koji poprima vrijednost 1 ako postoji veza između čvorova $i$ i $j$, odnosno 0 ako veza ne postoji. Drugim riječima, stupanj centralnosti jednostavno broji koliko izravnih veza čvor ima. Ako medij ima vezu s pet drugih medija, njegov stupanj iznosi pet. Za usporedbu mreža različitih veličina koristi se normalizirani stupanj centralnosti koji se dobiva dijeljenjem stupnja s maksimalnim mogućim brojem veza:
$$C_D^{norm}(i) = \frac{k_i}{n-1}$$
gdje je $n$ ukupan broj čvorova u mreži. Normalizirani stupanj izražava udio ostvarenih veza u maksimalnom mogućem broju veza i poprima vrijednosti između 0 i 1. Primjerice, ako mreža ima deset čvorova, a jedan čvor ima pet veza, njegov normalizirani stupanj iznosi 5/9, odnosno otprilike 0.56, što omogućuje usporedbu centralnosti čvorova u mrežama različitih veličina.
U **usmjerenim mrežama** razlikujemo dva tipa stupnja centralnosti. **Ulazni stupanj** (engl. *in-degree*) broji veze koje dolaze u čvor, dok **izlazni stupanj** (engl. *out-degree*) broji veze koje izlaze iz čvora. Ova distinkcija ima značajne implikacije za interpretaciju. U mreži citiranja akademskih radova, visok ulazni stupanj označava rad koji mnogi citiraju, što sugerira njegov utjecaj na polje. Visok izlazni stupanj označava rad s mnogim referencama, što može indicirati pregledni članak ili sintezu literature. U kontekstu Twittera, ulazni stupanj odgovara broju pratitelja, a izlazni stupanj broju praćenih računa. U R-u se stupanj centralnosti izračunava pozivom funkcije `degree()` iz paketa `igraph`, pri čemu argument `mode` može poprimiti vrijednosti `"in"`, `"out"` ili `"all"` za usmjerene mreže, a normalizirani oblik dobiva se dijeljenjem rezultata s brojem čvorova umanjenim za jedan.
```{r}
#| label: fig-degree-centrality
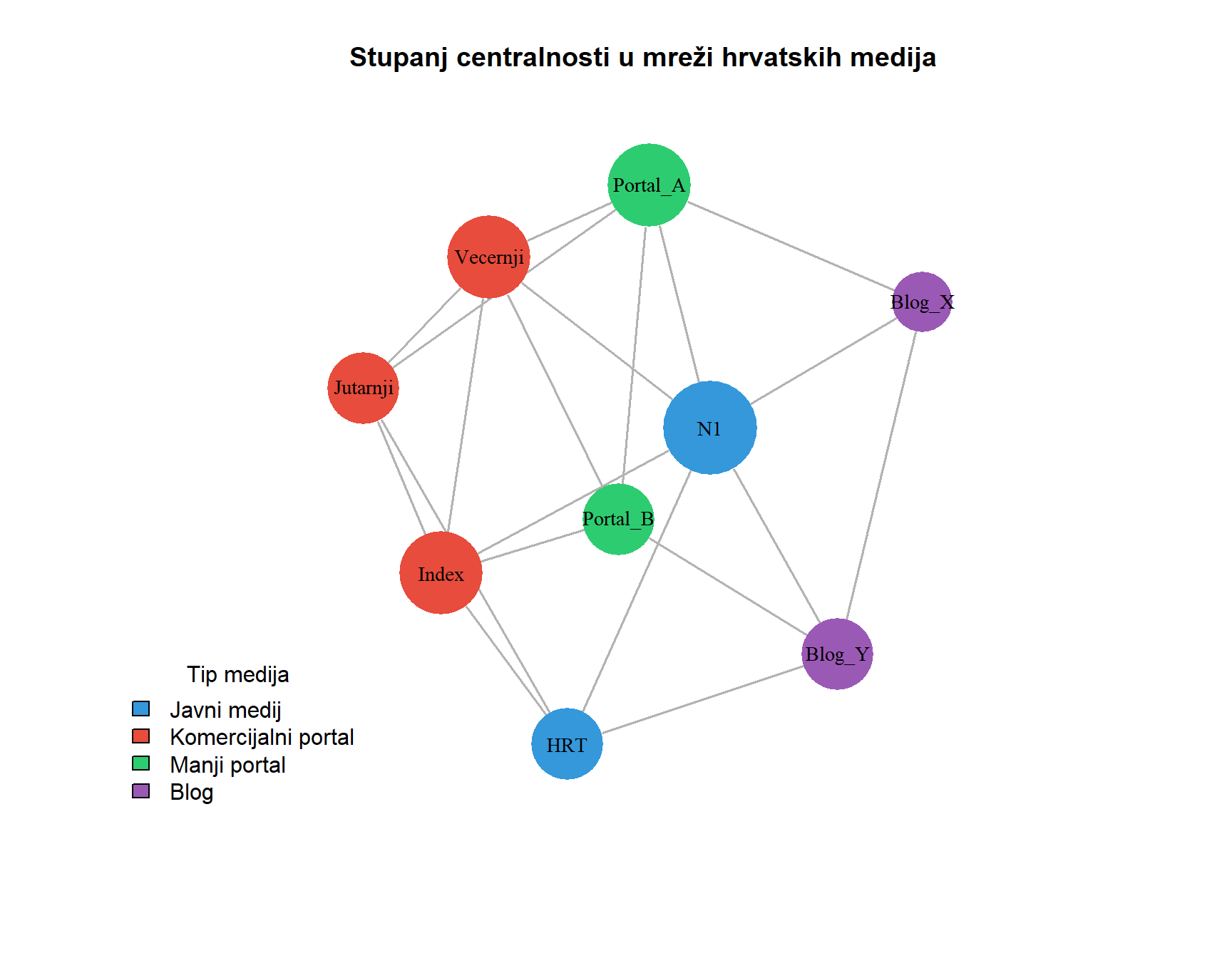
#| fig-cap: "Vizualizacija stupnja centralnosti u hipotetskoj mreži hrvatskih medija. Veličina čvora proporcionalna je stupnju centralnosti, a boja označava tip medija. Čvorovi s višim stupnjem centralnosti (poput N1 i Indexa) nalaze se u središtu mreže s najviše izravnih veza."
#| fig-width: 9
#| fig-height: 7
# Izračun stupnja centralnosti za svaki čvor
V(media_net)$degree <- degree(media_net)
# Definiranje boja prema tipu medija
degree_colors <- c("Javni medij" = "#3498db", "Komercijalni portal" = "#e74c3c",
"Manji portal" = "#2ecc71", "Blog" = "#9b59b6")
set.seed(42)
# Veličina čvora proporcionalna stupnju centralnosti
plot(media_net,
vertex.size = V(media_net)$degree * 4 + 10,
vertex.color = degree_colors[V(media_net)$type],
vertex.frame.color = NA,
vertex.label.color = "black",
vertex.label.cex = 0.9,
vertex.label.dist = 0,
edge.color = "gray70",
edge.width = 1.5,
main = "Stupanj centralnosti u mreži hrvatskih medija")
legend("bottomleft",
legend = names(degree_colors),
fill = degree_colors,
title = "Tip medija",
bty = "n")
```
```{r}
#| label: tbl-degree
#| tbl-cap: "Stupanj centralnosti za svaki čvor u mreži hrvatskih medija. Viši stupanj označava veći broj izravnih veza s drugim medijima u mreži."
# Izračun stupnja i normaliziranog stupnja za svaki čvor
degree_df <- data.frame(
Medij = V(media_net)$name,
Tip = V(media_net)$type,
Stupanj = degree(media_net),
Normalizirani_stupanj = round(degree(media_net) / (vcount(media_net) - 1), 3)
)
# Sortiranje prema stupnju (od najvišeg prema najnižem)
degree_df <- degree_df[order(-degree_df$Stupanj), ]
kable(degree_df,
col.names = c("Medij", "Tip", "Stupanj", "Normalizirani stupanj"),
row.names = FALSE) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = FALSE)
```
U kontekstu istraživanja masovne komunikacije, stupanj centralnosti može se interpretirati kao mjera **vidljivosti** ili **popularnosti**. Medij s visokim stupnjem centralnosti u mreži citiranja jest medij kojeg mnogi drugi mediji citiraju kao izvor, što sugerira njegov status autoritativnog izvora informacija. Na društvenim mrežama, korisnik s visokim stupnjem centralnosti jest korisnik s mnogo pratitelja ili prijatelja, što mu daje potencijalnu publiku za širenje poruka. Međutim, važno je napomenuti da stupanj centralnosti mjeri samo lokalne veze i ne uzima u obzir globalnu strukturu mreže. Čvor može imati visok stupanj, ali biti povezan samo s marginaliziranim dijelom mreže, što ograničava njegov stvarni utjecaj. Stupanj centralnosti pruža uvid u lokalnu istaknutost čvora, no za razumijevanje globalne uloge aktera u mreži potrebno je razmotriti i položaj čvora na putanjama koje povezuju druge čvorove.
## Međuposredovanje
Dok stupanj centralnosti mjeri izravne veze čvora, **međuposredovanje** (engl. *betweenness centrality*) hvata različit aspekt važnosti koji se odnosi na poziciju čvora na putanjama koje povezuju druge čvorove u mreži. Intuitivno, čvor ima visoko međuposredovanje ako se nalazi na mnogim najkraćim putanjama između drugih parova čvorova. Takav čvor djeluje kao most ili posrednik kroz kojeg moraju prolaziti informacije, resursi ili utjecaji koji se kreću mrežom. U kontekstu komunikacije, čvorovi s visokim međuposredovanjem mogu se konceptualizirati kao **gatekeeperi** koji kontroliraju tokove informacija.
Formalno, međuposredovanje čvora $i$ definira se kao:
$$C_B(i) = \sum_{s \neq i \neq t} \frac{\sigma_{st}(i)}{\sigma_{st}}$$
U ovoj formuli $\sigma_{st}$ označava ukupan broj najkraćih putanja između čvorova $s$ i $t$, dok $\sigma_{st}(i)$ označava broj tih putanja koje prolaze kroz čvor $i$. Intuitivno, formula broji za svaki par čvorova u mreži prolazi li najkraća putanja između njih kroz promatrani čvor. Čvor koji se nalazi na mnogim takvim putanjama ima visoko međuposredovanje jer djeluje kao neizbježan posrednik. Mjera sumira preko svih parova čvorova u mreži, kvantificirajući koliko često čvor $i$ leži na najkraćim putanjama. Normalizirana verzija dijeli se s maksimalnim mogućim brojem parova, omogućujući usporedbu među mrežama različitih veličina. Međuposredovanje se u R-u izračunava funkcijom `betweenness()` iz paketa `igraph`, pri čemu argument `normalized = TRUE` vraća normaliziranu vrijednost pogodnu za usporedbu među mrežama različitih veličina.
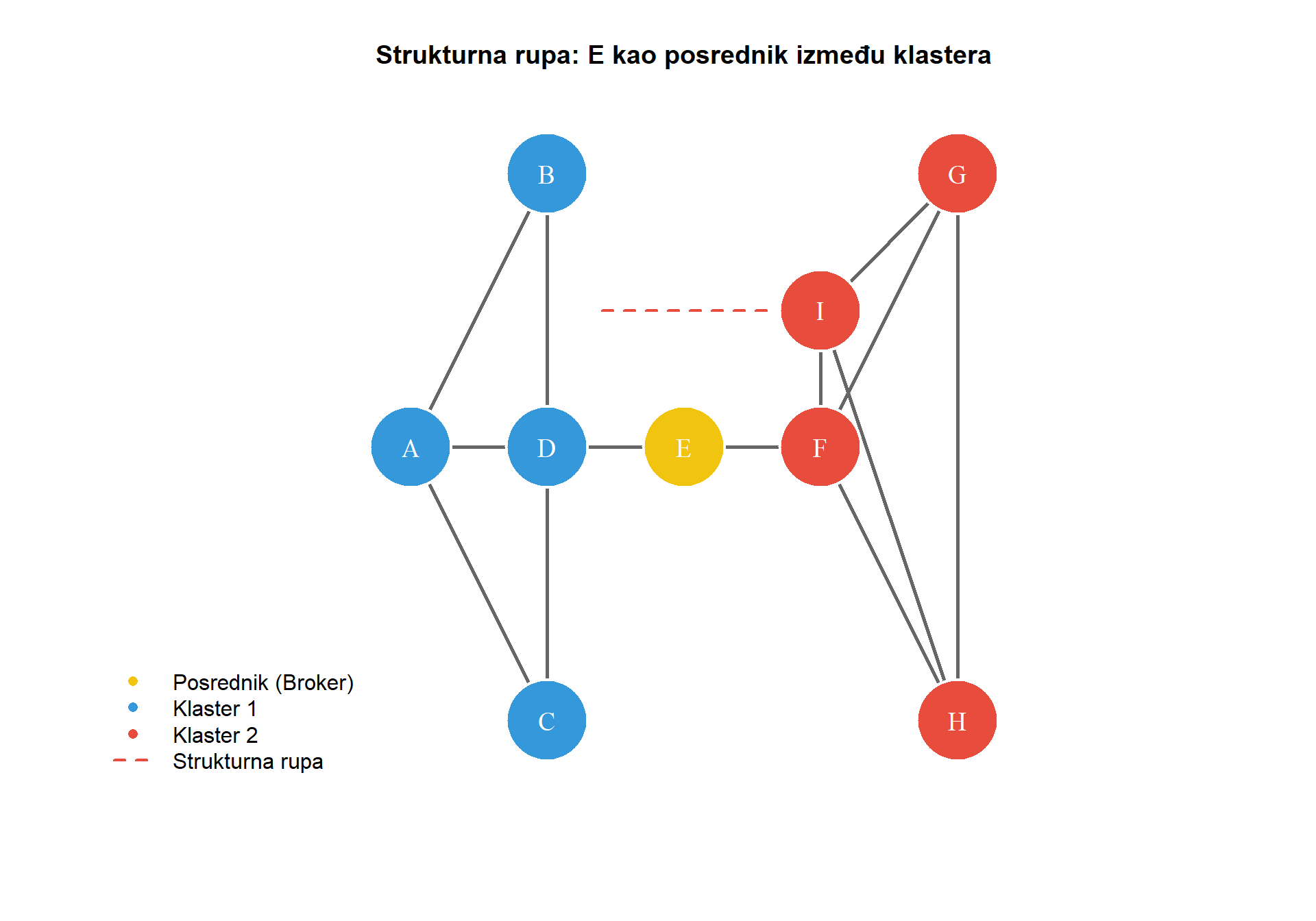
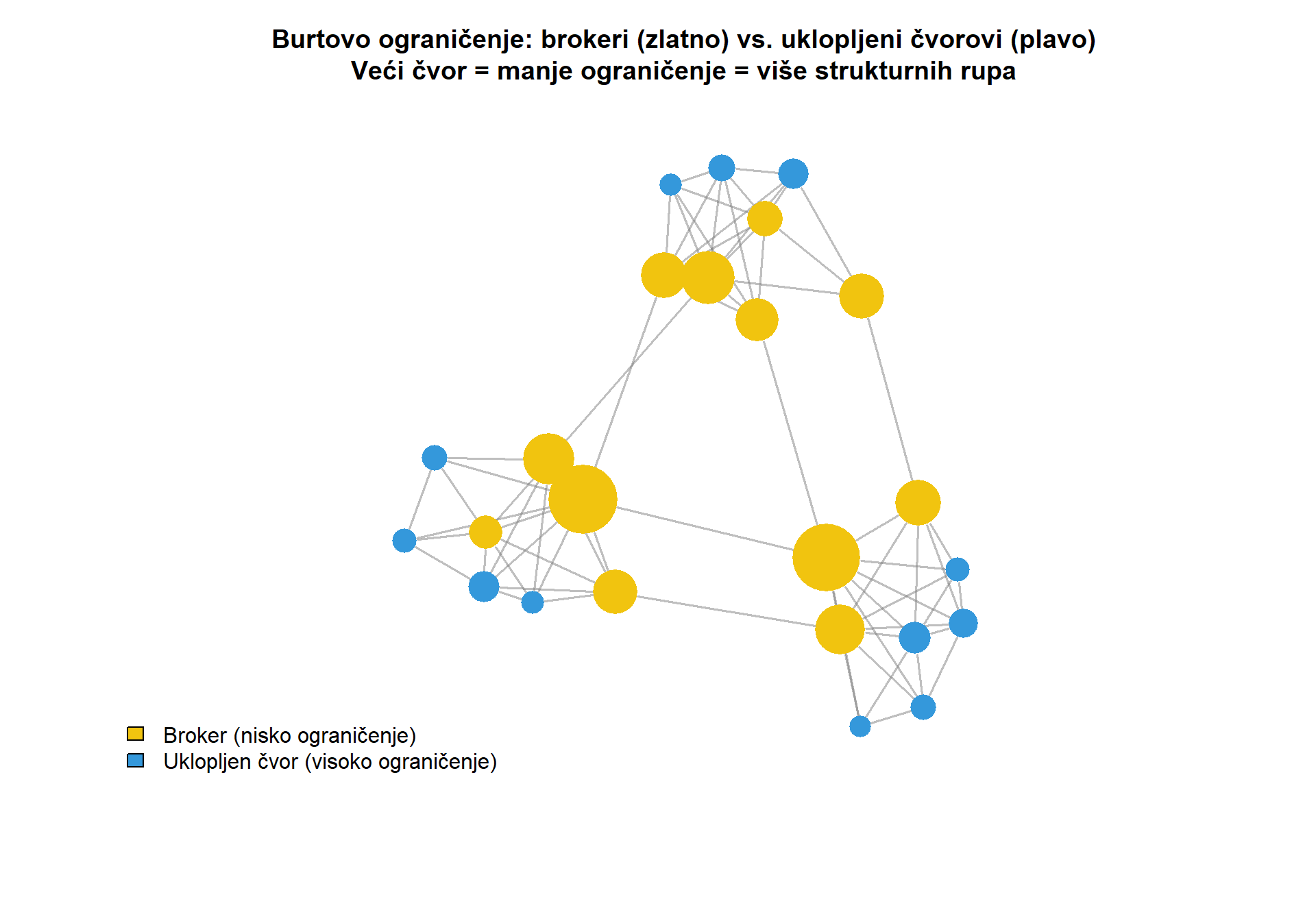
Konceptualna snaga međuposredovanja leži u njegovoj sposobnosti identificiranja čvorova koji povezuju inače odvojene dijelove mreže. U sociološkoj literaturi, takvi čvorovi opisuju se kao zauzimatelji **strukturnih rupa**, pojam koji je uveo Ronald Burt. Strukturna rupa jest praznina u mreži gdje određeni čvor premošćuje dva klastera koji inače ne bi bili povezani. Akter koji premošćuje strukturnu ruku ima pristup raznolikim izvorima informacija i može djelovati kao posrednik između različitih skupina, što mu daje značajnu moć i pristup neredundantnim informacijama.
```{r}
#| label: fig-betweenness
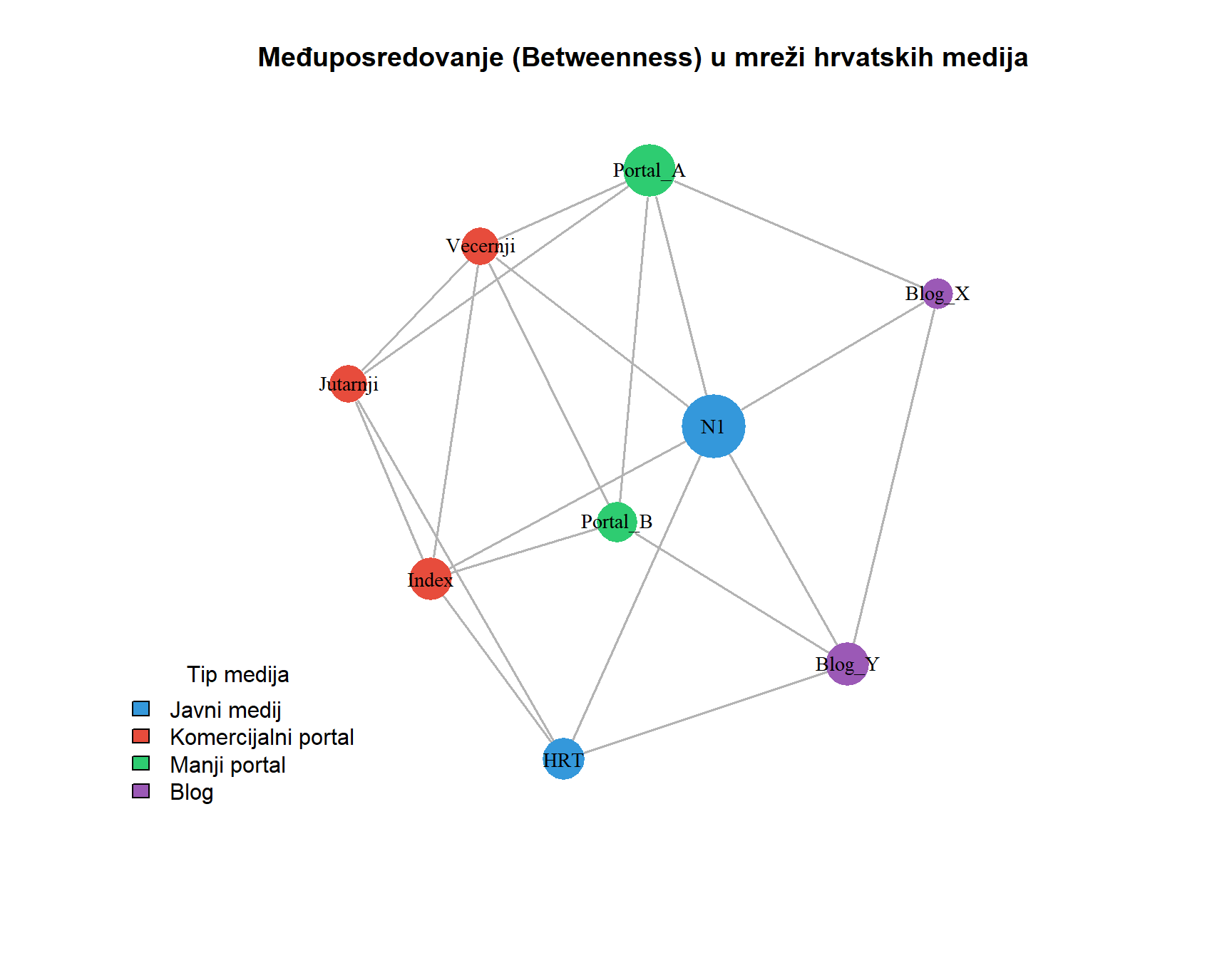
#| fig-cap: "Vizualizacija međuposredovanja u mreži hrvatskih medija. Veličina čvora proporcionalna je međuposredovanju. Čvorovi s visokim međuposredovanjem (poput Portala_A) djeluju kao mostovi između različitih dijelova mreže i kontroliraju protok informacija."
#| fig-width: 9
#| fig-height: 7
# Izračun normaliziranog međuposredovanja
V(media_net)$betweenness <- betweenness(media_net, normalized = TRUE)
set.seed(42)
# Veličina čvora proporcionalna međuposredovanju
plot(media_net,
vertex.size = V(media_net)$betweenness * 80 + 10,
vertex.color = degree_colors[V(media_net)$type],
vertex.frame.color = NA,
vertex.label.color = "black",
vertex.label.cex = 0.9,
edge.color = "gray70",
edge.width = 1.5,
main = "Međuposredovanje (Betweenness) u mreži hrvatskih medija")
legend("bottomleft",
legend = names(degree_colors),
fill = degree_colors,
title = "Tip medija",
bty = "n")
```
```{r}
#| label: tbl-betweenness
#| tbl-cap: "Međuposredovanje (betweenness centrality) za svaki čvor u mreži. Viša vrijednost označava čvor koji se nalazi na više najkraćih putanja između drugih čvorova, djelujući kao most u mreži."
# Izračun apsolutnog i normaliziranog međuposredovanja
betweenness_df <- data.frame(
Medij = V(media_net)$name,
Tip = V(media_net)$type,
Meduposredovanje = round(betweenness(media_net), 2),
Normalizirano = round(betweenness(media_net, normalized = TRUE), 3)
)
# Sortiranje prema međuposredovanju
betweenness_df <- betweenness_df[order(-betweenness_df$Meduposredovanje), ]
kable(betweenness_df,
col.names = c("Medij", "Tip", "Međuposredovanje", "Normalizirano"),
row.names = FALSE) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = FALSE)
```
U istraživanjima masovne komunikacije, međuposredovanje je posebno relevantno za identificiranje gatekeepera, odnosno aktera koji kontroliraju pristup informacijama između različitih skupina. Novinar koji povezuje političke elite s javnošću, agregator vijesti koji povezuje mainstream medije s alternativnim portalima, ili influencer koji premošćuje ideološki različite online zajednice, svi oni imaju potencijalno visoko međuposredovanje. Ovi akteri mogu imati disproporcionalan utjecaj na to koje informacije cirkuliraju mrežom i kako se oblikuje javni diskurs.
Praktična ilustracija dolazi iz istraživanja širenja dezinformacija. Čak i ako dezinformacijski portal ima relativno malo pratitelja (nizak stupanj), može imati visoko međuposredovanje ako ga retweetaju korisnici koji povezuju mainstream i alternativne medijske prostore. Identificiranje takvih mostova može biti ključno za razumijevanje mehanizama širenja dezinformacija i potencijalne intervencije. Dok međuposredovanje mjeri kontrolu nad protocima u mreži, sljedeća mjera centralnosti, bliskost, fokusira se na pitanje koliko učinkovito čvor može doprijeti do svih ostalih čvorova.
## Bliskost
Treća klasična mjera centralnosti jest **bliskost** (engl. *closeness centrality*) koja mjeri koliko je čvor blizu svim ostalim čvorovima u mreži u terminima prosječne udaljenosti. Intuitivno, čvor s visokom bliskošću može brzo doći do svakog drugog čvora u mreži, odnosno informacija koja kreće od tog čvora prosječno treba manje koraka da dosegne bilo koji drugi čvor. U kontekstu komunikacije, visoka bliskost može se interpretirati kao **komunikacijska učinkovitost** jer omogućuje brzo širenje poruka kroz mrežu.
Formalno, bliskost čvora $i$ definira se kao recipročna vrijednost prosječne udaljenosti od tog čvora do svih ostalih čvorova:
$$C_C(i) = \frac{n-1}{\sum_{j \neq i} d(i,j)}$$
U ovoj formuli $d(i,j)$ označava duljinu najkraće putanje između čvorova $i$ i $j$, a $n$ je ukupan broj čvorova. Brojnik $n-1$ služi normalizaciji tako da maksimalna moguća vrijednost iznosi 1 kada je čvor izravno povezan sa svim ostalim čvorovima. Formula izračunava prosječnu udaljenost od promatranog čvora do svih ostalih čvorova, a zatim tu vrijednost invertira tako da viša vrijednost označava veću bliskost. Čvor koji je u prosjeku udaljen dva koraka od svih ostalih čvorova imat će veću bliskost od čvora koji je u prosjeku udaljen četiri koraka. U R-u se bliskost izračunava funkcijom `closeness()` iz paketa `igraph`, pri čemu argument `normalized = TRUE` vraća normaliziranu vrijednost.
```{r}
#| label: fig-closeness
#| fig-cap: "Vizualizacija bliskosti (closeness centrality) u mreži hrvatskih medija. Veličina čvora proporcionalna je bliskosti. Čvorovi s visokom bliskošću mogu najučinkovitije širiti informacije jer su prosječno najbliži svim ostalim čvorovima u mreži."
#| fig-width: 9
#| fig-height: 7
# Izračun normalizirane bliskosti za svaki čvor
V(media_net)$closeness <- closeness(media_net, normalized = TRUE)
set.seed(42)
# Veličina čvora proporcionalna bliskosti
plot(media_net,
vertex.size = V(media_net)$closeness * 50 + 5,
vertex.color = degree_colors[V(media_net)$type],
vertex.frame.color = NA,
vertex.label.color = "black",
vertex.label.cex = 0.9,
edge.color = "gray70",
edge.width = 1.5,
main = "Bliskost (Closeness) u mreži hrvatskih medija")
legend("bottomleft",
legend = names(degree_colors),
fill = degree_colors,
title = "Tip medija",
bty = "n")
```
```{r}
#| label: tbl-closeness
#| tbl-cap: "Bliskost (closeness centrality) za svaki čvor u mreži. Viša vrijednost označava čvor koji je prosječno bliži svim ostalim čvorovima i može najučinkovitije širiti informacije kroz mrežu."
# Izračun apsolutne i normalizirane bliskosti
closeness_df <- data.frame(
Medij = V(media_net)$name,
Tip = V(media_net)$type,
Bliskost = round(closeness(media_net), 4),
Normalizirana = round(closeness(media_net, normalized = TRUE), 3)
)
# Sortiranje prema bliskosti
closeness_df <- closeness_df[order(-closeness_df$Bliskost), ]
kable(closeness_df,
col.names = c("Medij", "Tip", "Bliskost", "Normalizirana"),
row.names = FALSE) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = FALSE)
```
Važno ograničenje bliskosti jest njezina osjetljivost na nepovezane mreže. Ako mreža ima više komponenti koje nisu međusobno povezane, udaljenost između čvorova u različitim komponentama je beskonačna, što čini standardnu formulu neupotrebljivom. U takvim slučajevima koriste se modificirane verzije mjere ili se analiza ograničava na najveću povezanu komponentu mreže.
U kontekstu istraživanja masovne komunikacije, bliskost je relevantna za razumijevanje dinamike širenja informacija. Medij ili korisnik s visokom bliskošću jest potencijalno učinkovit širitelj informacija jer njegove poruke mogu brzo doseći sve dijelove mreže. Ova mjera može biti korisna za identificiranje potencijalnih ambasadora kampanja ili, s druge strane, potencijalnih širitelja dezinformacija koji mogu brzo kontaminirati cijelu mrežu. Dosad razmatrane mjere tretiraju sve veze kao jednako vrijedne, no u praksi je jasno da veza s utjecajnim akterom nosi drugačiju težinu od veze s perifernim sudionikom.
## Svojstvena vektorska centralnost
Sve dosad razmatrane mjere tretiraju sve veze kao jednako vrijedne. Međutim, intuitivno je jasno da veza s utjecajnim čvorom vrijedi više od veze s marginalnim čvorom. Osoba koja poznaje predsjednika države ima više potencijalnog utjecaja od osobe koja poznaje samo svoje susjede, čak i ako obje imaju jednak broj poznanika. **Svojstvena vektorska centralnost** (engl. *eigenvector centrality*) formalizira ovu intuiciju definirajući centralnost čvora kao funkciju centralnosti njegovih susjeda. Čvor je centralan ako je povezan s drugim centralnim čvorovima.
Ova rekurzivna definicija može se matematički izraziti kao:
$$C_E(i) = \frac{1}{\lambda} \sum_{j} a_{ij} C_E(j)$$
U ovoj formuli $C_E(i)$ označava svojstvenu vektorsku centralnost čvora $i$, $a_{ij}$ je element matrice susjedstva, a $\lambda$ je konstanta normalizacije. Jednostavnije rečeno, centralnost čvora izračunava se kao prosjek centralnosti njegovih susjeda. Čvor koji je povezan s tri visoko centralna čvora bit će centralniji od čvora koji je povezan s tri periferna čvora, čak i ako oba imaju jednak broj veza.^[U matričnom obliku, vektor centralnosti $\mathbf{x}$ zadovoljava jednadžbu $A\mathbf{x} = \lambda\mathbf{x}$, gdje je $A$ matrica susjedstva, a $\lambda$ najveća svojstvena vrijednost te matrice. Vektor $\mathbf{x}$ koji odgovara ovoj najvećoj svojstvenoj vrijednosti jest vektor svojstvenih vektorskih centralnosti. Detaljniji opis matrične algebre koja stoji iza ovog izračuna može se pronaći u Barabasi (2016).]
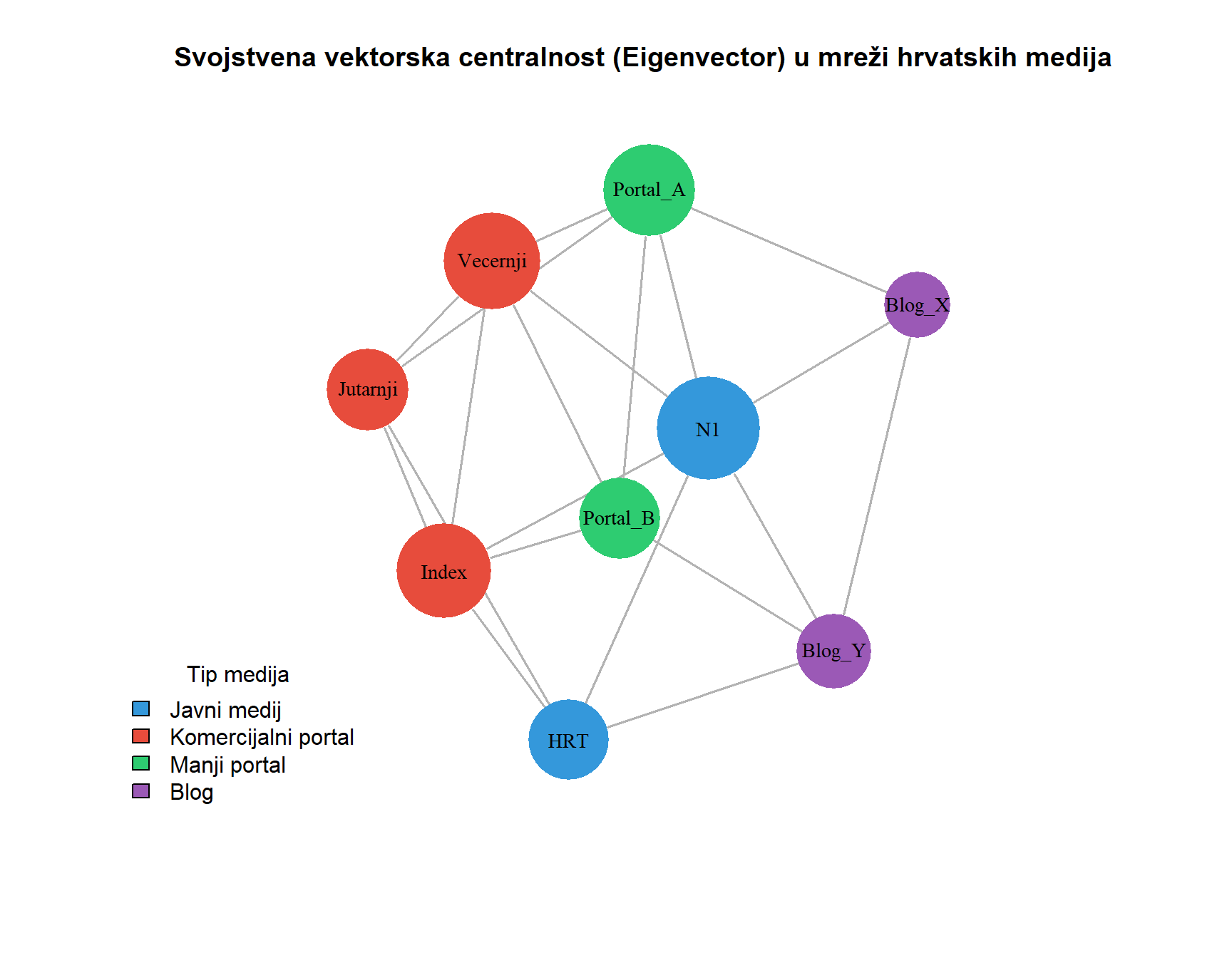
Konceptualna snaga ove mjere leži u tome što uzima u obzir ne samo izravne veze čvora, već i kvalitetu tih veza mjerenu centralnošću susjeda. Čvor može imati umjeren stupanj, ali visoku svojstvenu vektorsku centralnost ako je povezan s nekoliko visoko centralnih čvorova. Obratno, čvor s visokim stupnjem može imati relativno nisku svojstvenu vektorsku centralnost ako su svi njegovi susjedi periferni. U R-u se svojstvena vektorska centralnost izračunava funkcijom `eigen_centrality()` iz paketa `igraph`, koja vraća listu čija komponenta `$vector` sadrži vrijednosti centralnosti za svaki čvor.
```{r}
#| label: fig-eigenvector
#| fig-cap: "Vizualizacija svojstvene vektorske centralnosti u mreži hrvatskih medija. Veličina čvora proporcionalna je centralnosti. Ova mjera nagrađuje čvorove koji su povezani s drugim utjecajnim čvorovima, a ne samo broj veza."
#| fig-width: 9
#| fig-height: 7
# Izračun svojstvene vektorske centralnosti
V(media_net)$eigenvector <- eigen_centrality(media_net)$vector
set.seed(42)
# Veličina čvora proporcionalna svojstvenoj vektorskoj centralnosti
plot(media_net,
vertex.size = V(media_net)$eigenvector * 30 + 8,
vertex.color = degree_colors[V(media_net)$type],
vertex.frame.color = NA,
vertex.label.color = "black",
vertex.label.cex = 0.9,
edge.color = "gray70",
edge.width = 1.5,
main = "Svojstvena vektorska centralnost (Eigenvector) u mreži hrvatskih medija")
legend("bottomleft",
legend = names(degree_colors),
fill = degree_colors,
title = "Tip medija",
bty = "n")
```
**PageRank**, algoritam koji je Google koristio za rangiranje web stranica, predstavlja varijantu svojstvene vektorske centralnosti prilagođenu usmjerenim mrežama. Osnovna intuicija je ista: stranica je važna ako na nju upućuju važne stranice. PageRank uključuje dodatne modifikacije poput faktora prigušenja koji rješava probleme s čvorovima bez izlaznih veza. U kontekstu istraživanja medija, PageRank se može primijeniti na mreže hiperlinkova kako bi se identificirali najutjecajniji online izvori. U R-u se PageRank izračunava funkcijom `page_rank()` iz paketa `igraph`.
```{r}
#| label: tbl-eigenvector
#| tbl-cap: "Svojstvena vektorska centralnost za svaki čvor u mreži. Viša vrijednost označava čvor koji je povezan s drugim utjecajnim čvorovima."
# Izračun svojstvene vektorske centralnosti za tablični prikaz
eigen_df <- data.frame(
Medij = V(media_net)$name,
Tip = V(media_net)$type,
Eigenvector = round(eigen_centrality(media_net)$vector, 4)
)
# Sortiranje prema centralnosti
eigen_df <- eigen_df[order(-eigen_df$Eigenvector), ]
kable(eigen_df,
col.names = c("Medij", "Tip", "Svojstvena vekt. centralnost"),
row.names = FALSE) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = FALSE)
```
U istraživanjima masovne komunikacije, svojstvena vektorska centralnost je korisna za identificiranje aktera čiji utjecaj proizlazi iz veza s drugim utjecajnim akterima. Novinar koji ima pristup elitnim izvorima, komentator kojeg citiraju drugi utjecajni komentatori, ili portal kojeg dijele mainstream mediji, svi oni mogu imati visoku svojstvenu vektorsku centralnost čak i ako njihov ukupni broj veza nije među najvećima. Ova mjera posebno je relevantna za razumijevanje elite mrežne strukture i identifikaciju aktera koji su utjecajni ne zbog svoje vidljivosti, već zbog kvalitete svojih veza. S obzirom na to da svaka od opisanih mjera operacionalizira drugačiji koncept važnosti, korisno je usporediti njihove rezultate na istoj mreži kako bi se uočile sličnosti i razlike u rangiranju aktera.
## Usporedba mjera centralnosti
Različite mjere centralnosti hvataju različite aspekte važnosti čvora u mreži i mogu proizvoditi značajno različite rangove istih čvorova. Razumijevanje ovih razlika ključno je za odabir odgovarajuće mjere s obzirom na istraživačko pitanje.
```{r}
#| label: fig-centrality-comparison
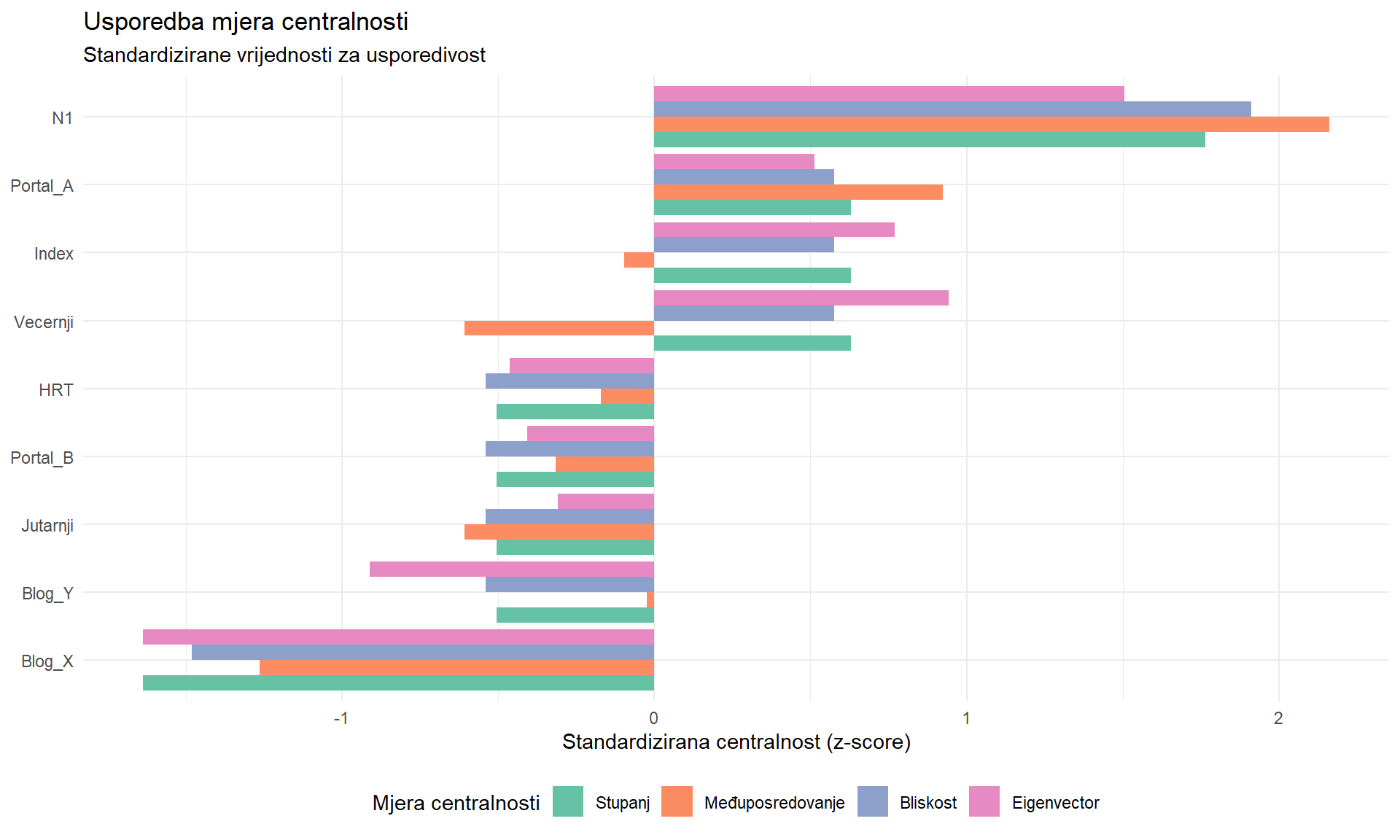
#| fig-cap: "Usporedba četiri mjere centralnosti za sve čvorove u mreži hrvatskih medija. Različite mjere mogu značajno različito rangirati iste čvorove ovisno o aspektu važnosti koji mjere."
#| fig-width: 10
#| fig-height: 6
# Izračun i standardizacija svih mjera centralnosti
centrality_df <- data.frame(
Medij = V(media_net)$name,
Stupanj = scale(degree(media_net))[,1],
Meduposredovanje = scale(betweenness(media_net))[,1],
Bliskost = scale(closeness(media_net))[,1],
Eigenvector = scale(eigen_centrality(media_net)$vector)[,1]
)
# Pretvaranje u dugi format za vizualizaciju
centrality_long <- centrality_df |>
pivot_longer(cols = -Medij, names_to = "Mjera", values_to = "Vrijednost")
centrality_long$Mjera <- factor(centrality_long$Mjera,
levels = c("Stupanj", "Meduposredovanje", "Bliskost", "Eigenvector"),
labels = c("Stupanj", "Međuposredovanje", "Bliskost", "Eigenvector"))
# Usporedni stupčasti dijagram
ggplot(centrality_long, aes(x = reorder(Medij, Vrijednost), y = Vrijednost, fill = Mjera)) +
geom_col(position = "dodge") +
coord_flip() +
scale_fill_brewer(palette = "Set2") +
labs(
title = "Usporedba mjera centralnosti",
subtitle = "Standardizirane vrijednosti za usporedivost",
x = NULL,
y = "Standardizirana centralnost (z-score)",
fill = "Mjera centralnosti"
) +
theme_minimal(base_size = 11) +
theme(legend.position = "bottom")
```
Sljedeća tablica sažima vrijednosti svih četiriju mjera centralnosti za sve čvorove u primjeru mreže hrvatskih medija.
```{r}
#| label: tbl-all-centrality
#| tbl-cap: "Sažetak svih mjera centralnosti za mrežu hrvatskih medija. Svaka mjera hvata različit aspekt važnosti čvora u mrežnoj strukturi."
# Zbirni prikaz svih mjera centralnosti
all_centrality <- data.frame(
Medij = V(media_net)$name,
Tip = V(media_net)$type,
Stupanj = degree(media_net),
Meduposredovanje = round(betweenness(media_net, normalized = TRUE), 3),
Bliskost = round(closeness(media_net, normalized = TRUE), 3),
Eigenvector = round(eigen_centrality(media_net)$vector, 3)
)
# Sortiranje prema stupnju centralnosti
all_centrality <- all_centrality[order(-all_centrality$Stupanj), ]
kable(all_centrality,
col.names = c("Medij", "Tip", "Stupanj", "Međuposr.", "Bliskost", "Eigenvector"),
row.names = FALSE) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Iz tablice je vidljivo da čvorovi s najviše izravnih veza (stupanj) ne moraju nužno dominirati i po ostalim mjerama. Portal_A, primjerice, može imati natproporcionalno visoko međuposredovanje u odnosu na svoj stupanj, što upućuje na njegovu ulogu posrednika između različitih segmenata mreže. Sljedeća tablica sažima interpretacije različitih mjera centralnosti u kontekstu istraživanja masovne komunikacije.
```{r}
#| label: tbl-interpretation
#| tbl-cap: "Interpretacija mjera centralnosti u kontekstu istraživanja masovne komunikacije."
# Tablica koja povezuje svaku mjeru s odgovarajućim istraživačkim pitanjem
interpretation_df <- data.frame(
Mjera = c("Stupanj", "Međuposredovanje", "Bliskost", "Eigenvector/PageRank"),
Pitanje = c(
"Koliko je akter vidljiv/popularan?",
"Kontrolira li akter protok informacija?",
"Koliko učinkovito akter može širiti poruke?",
"Je li akter povezan s drugim važnim akterima?"
),
Primjer_visokog = c(
"Mainstream medij s mnogo pratitelja",
"Agregator koji povezuje različite izvore",
"Centralno pozicionirani portal",
"Novinar s pristupom elitnim izvorima"
),
Komunikacijski_koncept = c(
"Doseg, vidljivost, popularnost",
"Gatekeeping, kontrola informacija",
"Učinkovitost difuzije",
"Elitni utjecaj, prestiž"
)
)
kable(interpretation_df,
col.names = c("Mjera", "Pitanje koje odgovara", "Primjer visokog rezultata", "Komunikacijski koncept")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Tablica pokazuje da je izbor mjere centralnosti neodvojiv od teorijskog pitanja koje istraživač postavlja, stoga analiza koja se oslanja na samo jednu mjeru nužno daje nepotpunu sliku mrežne strukture. Izbor mjere centralnosti treba biti vođen teorijskim pitanjem koje istraživač postavlja. Ako je u fokusu pitanje tko je najpopularniji ili najvidljiviji akter, stupanj centralnosti jest prirodan izbor. Ako je u fokusu pitanje tko kontrolira tokove informacija između različitih skupina, međuposredovanje je prikladnije. Ako se istražuje potencijal za brzo širenje poruka, bliskost je relevantna mjera. Ako je u fokusu pristup elitnim krugovima ili utjecaj koji proizlazi iz kvalitete veza, svojstvena vektorska centralnost ili PageRank pružaju odgovarajuće uvide. U praksi, sveobuhvatna analiza često uključuje izračun više mjera centralnosti i usporedbu dobivenih rezultata, što omogućuje bogatiju interpretaciju mrežne strukture i uloga pojedinih aktera. Dosadašnja razmatranja bila su usmjerena na važnost pojedinačnih čvorova unutar mrežne strukture, no mreže posjeduju i globalna svojstva koja karakteriziraju sustav kao cjelinu, a upravo ta svojstva tema su sljedećeg odjeljka.
# Struktura mreže na makro razini
Dosadašnja razmatranja fokusirala su se na pojedinačne čvorove i njihovu relativnu važnost unutar mrežne strukture. Međutim, mreže posjeduju i globalna svojstva koja karakteriziraju strukturu kao cjelinu i koja se ne mogu svesti na karakteristike pojedinih čvorova. Zamislimo istraživača koji uspoređuje mrežu dijeljenja vijesti na Twitteru s mrežom citiranja među akademskim časopisima. Obje mreže mogu imati slične veličine u terminima broja čvorova i veza, no njihove globalne strukture mogu se dramatično razlikovati. Jedna može biti gusta i kohezivna, druga rijetka i fragmentirana. Jedna može pokazivati jasnu hijerarhiju s dominantnim čvorištima, druga može biti egalitarnija. Razumijevanje ovih makro karakteristika pruža uvide u temeljnu organizaciju komunikacijskog sustava i ima implikacije za procese poput širenja informacija, formiranja zajednica i otpornosti mreže na poremećaje.
Analiza strukture mreže na makro razini obuhvaća skup metrika i koncepata koji opisuju globalnu organizaciju mrežne strukture. Ove mjere omogućuju usporedbu različitih mreža, praćenje evolucije iste mreže kroz vrijeme i testiranje hipoteza o procesima koji su generirali promatranu strukturu. Takvo testiranje hipoteza konceptualno je srodno logici statističkog zaključivanja obrađenoj u poglavlju 9, pri čemu se promatrana mrežna struktura uspoređuje s teoretskim modelima poput nasumičnih mreža. U ovom odjeljku razmatraju se tri ključna koncepta: gustoća koja mjeri ukupnu povezanost mreže, fenomen malog svijeta koji opisuje istovremenu prisutnost lokalne gustoće i globalnih prečaca, te mreže bez skale koje karakterizira ekstremna nejednakost u distribuciji veza.
```{r}
#| label: setup-section4
#| include: false
# učitavanje paketa za mrežnu analizu i vizualizaciju
library(igraph) # temeljni paket za analizu mreža
library(ggraph) # vizualizacija mreža temeljena na ggplot2
library(tidygraph) # manipulacija mrežnih podataka u tidy formatu
library(ggplot2) # vizualizacija podataka
library(dplyr) # manipulacija podataka
library(tidyr) # preoblikovanje podataka
library(knitr) # formatiranje tablica
library(kableExtra) # napredno formatiranje tablica
# postavljanje teme za vizualizacije
theme_set(theme_minimal(base_size = 12))
```
## Gustoća mreže
**Gustoća** (engl. *density*) predstavlja najjednostavniju globalnu mjeru mrežne strukture koja kvantificira udio realiziranih veza u odnosu na maksimalan mogući broj veza. Intuitivno, gustoća odgovara na pitanje koliko je mreža ispunjena vezama. U potpuno povezanoj mreži gdje svaki čvor ima vezu sa svakim drugim čvorom gustoća iznosi 1, dok u mreži bez ikakvih veza gustoća iznosi 0. Stvarne društvene mreže tipično imaju gustoću negdje između ovih ekstrema, a njezina konkretna vrijednost pruža uvid u kohezivnost i integriranost promatrane zajednice.
Formalno, gustoća neusmjerene mreže definira se kao omjer broja postojećih veza i maksimalnog mogućeg broja veza:
$$D = \frac{2m}{n(n-1)}$$
U ovoj formuli $m$ označava broj veza u mreži, a $n$ broj čvorova. Faktor 2 u brojniku proizlazi iz činjenice da je maksimalan broj veza u neusmjerenoj mreži jednak $\frac{n(n-1)}{2}$ jer svaki par čvorova može biti povezan najviše jednom vezom. Za usmjerene mreže formula se modificira jer svaki par čvorova može imati dvije veze (u oba smjera):
$$D_{usmjerena} = \frac{m}{n(n-1)}$$
Gustoća se u R-u izračunava funkcijom `edge_density()` iz paketa `igraph`.
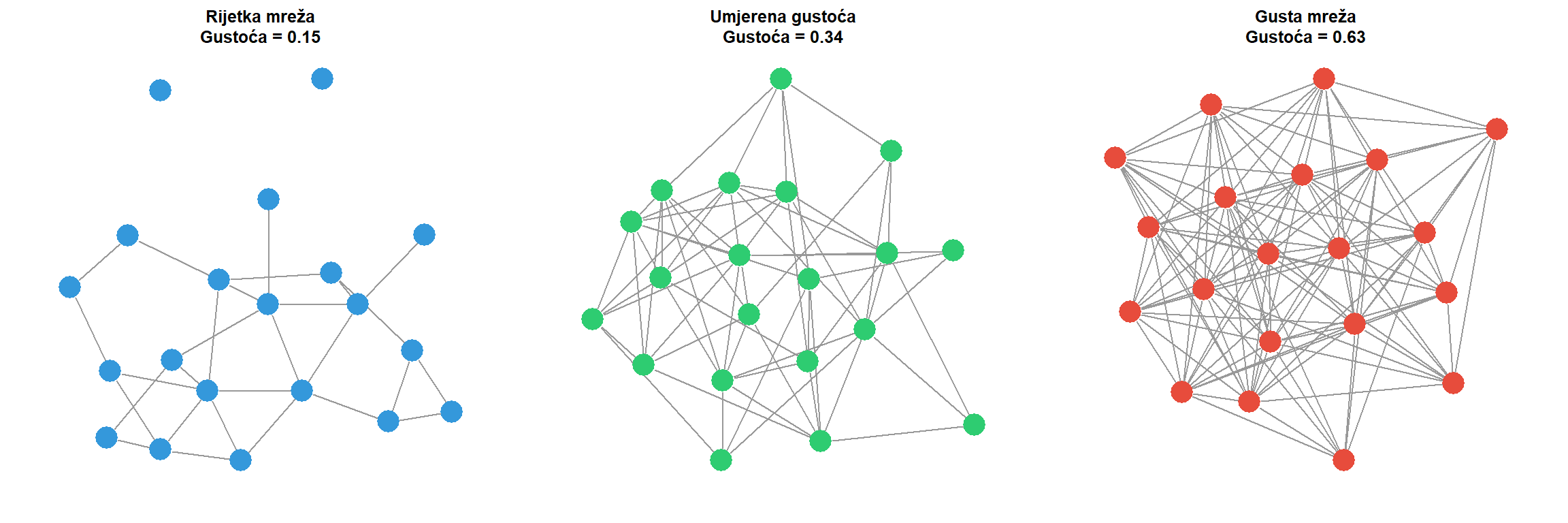
```{r}
#| label: fig-density-comparison
#| fig-cap: "Usporedba mreža različitih gustoća. Lijevo: rijetka mreža (gustoća oko 0.15) tipična za velike društvene mreže. Sredina: umjereno gusta mreža (gustoća oko 0.35) karakteristična za manje profesionalne zajednice. Desno: gusta mreža (gustoća oko 0.65) kakvu nalazimo u kohezivnim grupama poput redakcija ili timova."
#| fig-width: 12
#| fig-height: 4
set.seed(42)
# generiranje triju mreža s različitim razinama gustoće
sparse_net <- erdos.renyi.game(20, 0.15, type = "gnp")
medium_net <- erdos.renyi.game(20, 0.35, type = "gnp")
dense_net <- erdos.renyi.game(20, 0.65, type = "gnp")
# postavljanje parametara za usporedni prikaz
par(mfrow = c(1, 3), mar = c(2, 1, 3, 1))
# vizualizacija rijetke mreže
plot(sparse_net,
vertex.size = 12,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray60",
edge.width = 1.2,
main = paste0("Rijetka mreža\nGustoća = ", round(edge_density(sparse_net), 2)))
# vizualizacija umjereno guste mreže
plot(medium_net,
vertex.size = 12,
vertex.color = "#2ecc71",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray60",
edge.width = 1.2,
main = paste0("Umjerena gustoća\nGustoća = ", round(edge_density(medium_net), 2)))
# vizualizacija guste mreže
plot(dense_net,
vertex.size = 12,
vertex.color = "#e74c3c",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray60",
edge.width = 1.2,
main = paste0("Gusta mreža\nGustoća = ", round(edge_density(dense_net), 2)))
```
U kontekstu istraživanja masovne komunikacije, gustoća mreže može se interpretirati na nekoliko načina ovisno o tipu mreže koja se analizira. U mreži suradnje među novinarima, visoka gustoća sugerira kohezivnu profesionalnu zajednicu gdje većina novinara surađuje s većinom drugih novinara. Niska gustoća može indicirati fragmentiranu profesiju s izoliranim skupinama koje rijetko komuniciraju. U mreži dijeljenja sadržaja na društvenim mrežama, gustoća reflektira intenzitet interakcije među korisnicima. Visoka gustoća može sugerirati aktivnu i angažiranu zajednicu, dok niska gustoća može indicirati pasivniju publiku.
Važno je napomenuti da gustoća ima tendenciju opadanja s veličinom mreže. U maloj grupi od desetak ljudi relativno je lako održavati veze sa svima, no u mreži od tisuću ljudi to postaje praktički nemoguće. Stoga usporedba gustoća mreža različitih veličina zahtijeva oprez. Mreža od 50 čvorova s gustoćom 0.3 nije nužno manje kohezivna od mreže od 500 čvorova s gustoćom 0.05 jer veća mreža ima strukturna ograničenja koja onemogućuju visoku gustoću.
```{r}
#| label: tbl-density-examples
#| tbl-cap: "Tipične vrijednosti gustoće za različite tipove komunikacijskih mreža. Gustoća varira ovisno o veličini mreže i prirodi odnosa koji se modeliraju."
# tablica s primjerima tipičnih gustoća u komunikacijskim mrežama
density_examples <- data.frame(
Tip_mreze = c(
"Redakcija medijske kuće",
"Mreža novinara u državi",
"Pratitelji na Twitteru (uzorak)",
"Mreža citiranja među portalima",
"Globalna mreža hiperlinkova"
),
Tipicna_velicina = c("10-50", "100-500", "1.000-10.000", "50-200", "> 1.000.000"),
Ocekivana_gustoca = c("0.40 - 0.70", "0.05 - 0.15", "0.001 - 0.01", "0.10 - 0.30", "< 0.0001"),
Interpretacija = c(
"Visoka kohezija, česta suradnja",
"Umjerena povezanost profesije",
"Vrlo rijetka, selektivno praćenje",
"Umjerena, selektivno citiranje",
"Ekstremno rijetka, fragmentirana"
)
)
# formatiranje tablice
kable(density_examples,
col.names = c("Tip mreže", "Tipična veličina", "Očekivana gustoća", "Interpretacija")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Iz tablice je vidljivo da gustoća sustavno opada s porastom veličine mreže, što je strukturalno ograničenje koje valja uzeti u obzir pri usporedbi mreža različitih veličina.
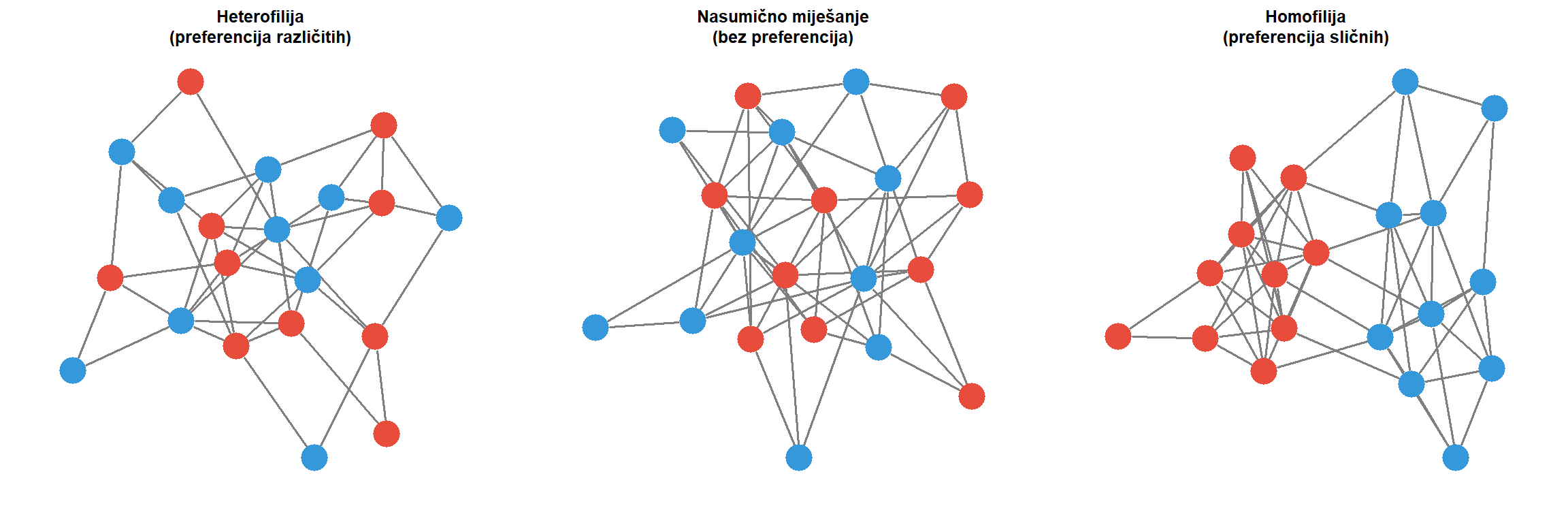
Osim ukupne gustoće, često je informativno računati **lokalnu gustoću** za pojedine dijelove mreže. Usporedba gustoće unutar identificiranih zajednica s ukupnom gustoćom mreže može otkriti stupanj modularnosti strukture. Ako su lokalne gustoće unutar zajednica značajno više od globalne gustoće, to sugerira jasno razdvojene i interno kohezivne skupine. Takva struktura tipična je za polarizirane online prostore gdje ideološki slične grupe intenzivno komuniciraju međusobno, ali rijetko s drugima.
Dok gustoća pruža uvid u ukupnu povezanost mreže, sljedeći odjeljak razmatra fascinantan fenomen koji objašnjava kako mreže istovremeno zadržavaju lokalnu kohezivnost i globalnu dostupnost.
## Fenomen malog svijeta
Jedno od najfascinantnijih otkrića mrežne znanosti jest da mnoge stvarne mreže pokazuju **fenomen malog svijeta** (engl. *small world phenomenon*). Ovo svojstvo, popularno poznato kao šest stupnjeva odvojenosti, označava da su čvorovi u mreži međusobno povezani iznenađujuće kratkim putanjama usprkos velikoj veličini mreže i relativno niskoj gustoći. Milgramov eksperiment iz 1967. godine empirijski je demonstrirao ovaj fenomen pokazavši da nasumično odabrani Amerikanci mogu biti povezani lancem od svega pet do šest poznanstava. Ovo otkriće izazvalo je duboko čuđenje jer intuitivno očekujemo da bi povezivanje dvaju stranaca u populaciji od stotina milijuna zahtijevalo mnogo dulji lanac.
Matematička analiza ovog fenomena pokazuje da mreže malog svijeta karakteriziraju dva naizgled proturječna svojstva. S jedne strane, pokazuju visok **koeficijent klasteriranja** (engl. *clustering coefficient*) koji mjeri tendenciju da prijatelji mojih prijatelja budu i moji prijatelji. Ovo svojstvo odražava lokalnu strukturu zajednica i klika. S druge strane, pokazuju kratku **prosječnu duljinu putanje** (engl. *average path length*) koja mjeri prosječan broj koraka potrebnih za povezivanje bilo koja dva čvora. Ovo svojstvo odražava postojanje prečaca koji povezuju udaljene dijelove mreže. Koeficijent klasteriranja izračunava se funkcijom `transitivity()` iz paketa `igraph`, pri čemu argument `type = "global"` vraća globalni koeficijent, a `type = "local"` lokalne koeficijente za svaki čvor. Prosječna duljina putanje izračunava se funkcijom `mean_distance()` iz paketa `igraph`.
**Koeficijent klasteriranja** za pojedini čvor $i$ definira se kao udio realiziranih veza među susjedima tog čvora u odnosu na maksimalan mogući broj veza:
$$C_i = \frac{2e_i}{k_i(k_i-1)}$$
U ovoj formuli $e_i$ označava broj veza među susjedima čvora $i$, a $k_i$ je stupanj čvora (broj susjeda). Globalni koeficijent klasteriranja dobiva se kao prosjek lokalnih koeficijenata preko svih čvorova. Visok koeficijent klasteriranja indicira da mreža sadrži mnogo zatvorenih trokuta, odnosno da postoji snažna tendencija formiranja gusto povezanih lokalnih zajednica.
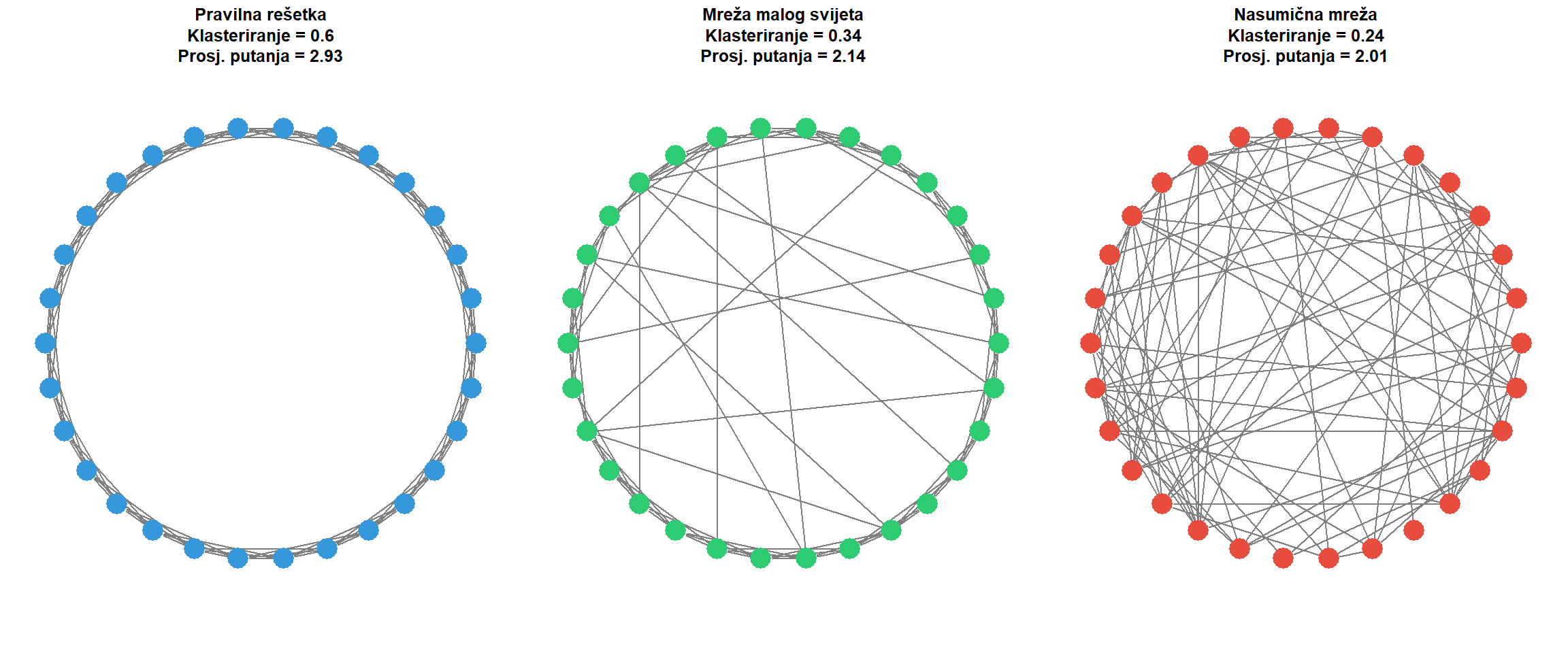
```{r}
#| label: fig-small-world
#| fig-cap: "Ilustracija fenomena malog svijeta kroz usporedbu tri tipa mreža s 30 čvorova. Lijevo: pravilna rešetka s visokim klasteriranjem ali dugim putanjama. Sredina: mreža malog svijeta (Watts-Strogatz) s visokim klasteriranjem i kratkim putanjama. Desno: nasumična mreža s niskim klasteriranjem i kratkim putanjama."
#| fig-width: 12
#| fig-height: 5
set.seed(123)
# generiranje pravilne rešetke kao polazišne strukture
lattice_net <- make_lattice(length = 30, dim = 1, nei = 3, circular = TRUE)
# generiranje mreže malog svijeta prema Watts-Strogatz modelu
small_world_net <- sample_smallworld(dim = 1, size = 30, nei = 3, p = 0.1)
# generiranje nasumične mreže za usporedbu
random_net <- erdos.renyi.game(30, p = edge_density(lattice_net), type = "gnp")
# postavljanje parametara za usporedni prikaz
par(mfrow = c(1, 3), mar = c(2, 1, 4, 1))
# vizualizacija pravilne rešetke
plot(lattice_net,
layout = layout_in_circle,
vertex.size = 10,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray50",
edge.width = 1.2,
main = paste0("Pravilna rešetka\nKlasteriranje = ", round(transitivity(lattice_net), 2),
"\nProsj. putanja = ", round(mean_distance(lattice_net), 2)))
# vizualizacija mreže malog svijeta
plot(small_world_net,
layout = layout_in_circle,
vertex.size = 10,
vertex.color = "#2ecc71",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray50",
edge.width = 1.2,
main = paste0("Mreža malog svijeta\nKlasteriranje = ", round(transitivity(small_world_net), 2),
"\nProsj. putanja = ", round(mean_distance(small_world_net), 2)))
# vizualizacija nasumične mreže
plot(random_net,
layout = layout_in_circle,
vertex.size = 10,
vertex.color = "#e74c3c",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray50",
edge.width = 1.2,
main = paste0("Nasumična mreža\nKlasteriranje = ", round(transitivity(random_net), 2),
"\nProsj. putanja = ", round(mean_distance(random_net), 2)))
```
Duncan Watts i Steven Strogatz 1998. godine predložili su elegantan model koji objašnjava kako mreže malog svijeta nastaju. Počevši od pravilne rešetke gdje je svaki čvor povezan samo s najbližim susjedima, nasumično preusmjeravamo mali udio veza prema udaljenim čvorovima. Ovi preusmjereni bridovi djeluju kao prečaci koji dramatično skraćuju prosječnu udaljenost u mreži, dok istovremeno zadržavaju visoko klasteriranje jer većina lokalnih veza ostaje netaknuta. Ključan uvid jest da je potreban samo mali broj prečaca da bi se prosječna putanja drastično skratila. Mreže malog svijeta generiraju se funkcijom `sample_smallworld()` iz paketa `igraph`.
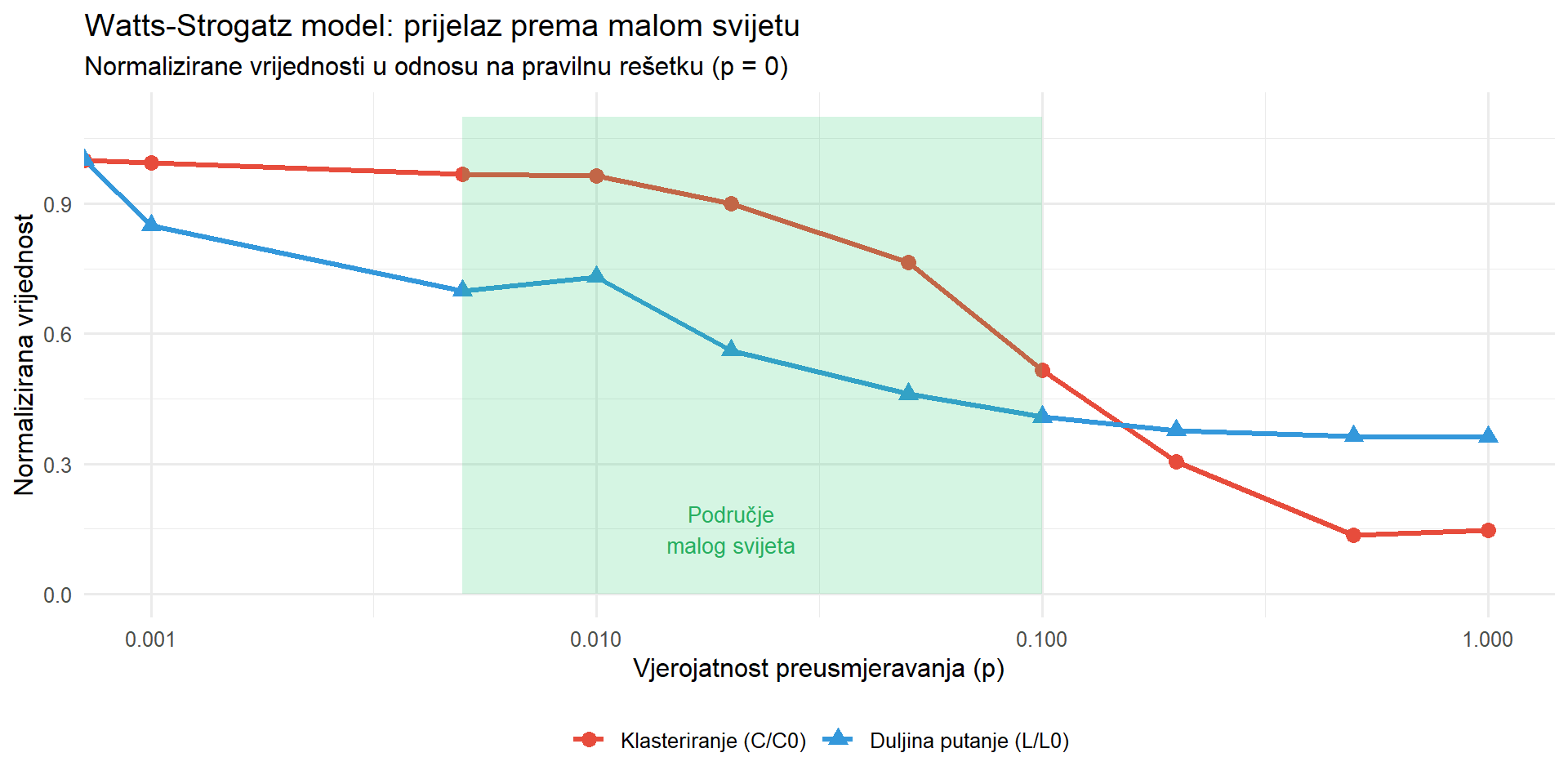
```{r}
#| label: fig-watts-strogatz
#| fig-cap: "Efekt dodavanja prečaca na svojstva mreže. S povećanjem vjerojatnosti preusmjeravanja (p), prosječna duljina putanje naglo opada dok klasteriranje opada postupno. Područje malog svijeta nalazi se pri niskim vrijednostima p gdje mreža zadržava visoko klasteriranje uz kratke putanje."
#| fig-width: 10
#| fig-height: 5
set.seed(42)
# definiranje raspona vjerojatnosti preusmjeravanja
p_values <- c(0, 0.001, 0.005, 0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1)
n_nodes <- 100
n_neighbors <- 4
# priprema podatkovnog okvira za rezultate simulacije
results <- data.frame(
p = numeric(),
clustering = numeric(),
path_length = numeric()
)
# izračun referentnih vrijednosti za pravilnu rešetku
base_lattice <- make_lattice(length = n_nodes, dim = 1, nei = n_neighbors, circular = TRUE)
base_clustering <- transitivity(base_lattice)
base_path <- mean_distance(base_lattice)
# iteracija po svim vrijednostima p
for (p in p_values) {
if (p == 0) {
net <- base_lattice
} else {
net <- sample_smallworld(dim = 1, size = n_nodes, nei = n_neighbors, p = p)
}
results <- rbind(results, data.frame(
p = p,
clustering = transitivity(net) / base_clustering,
path_length = mean_distance(net) / base_path
))
}
# pretvaranje u dugi format za vizualizaciju
results_long <- results |>
pivot_longer(cols = c(clustering, path_length),
names_to = "Mjera", values_to = "Vrijednost")
results_long$Mjera <- factor(results_long$Mjera,
levels = c("clustering", "path_length"),
labels = c("Klasteriranje (C/C0)", "Duljina putanje (L/L0)"))
ggplot(results_long, aes(x = p, y = Vrijednost, color = Mjera, shape = Mjera)) +
geom_line(linewidth = 1.2) +
geom_point(size = 3) +
scale_x_log10(labels = scales::label_number()) +
scale_color_manual(values = c("#e74c3c", "#3498db")) +
annotate("rect", xmin = 0.005, xmax = 0.1, ymin = 0, ymax = 1.1,
alpha = 0.2, fill = "#2ecc71") +
annotate("text", x = 0.02, y = 0.15, label = "Područje\nmalog svijeta",
size = 3.5, color = "#27ae60") +
labs(
title = "Watts-Strogatz model: prijelaz prema malom svijetu",
subtitle = "Normalizirane vrijednosti u odnosu na pravilnu rešetku (p = 0)",
x = "Vjerojatnost preusmjeravanja (p)",
y = "Normalizirana vrijednost",
color = NULL, shape = NULL
) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")
```
U kontekstu istraživanja masovne komunikacije, fenomen malog svijeta ima značajne implikacije za razumijevanje širenja informacija. Visoko klasteriranje znači da se informacije učinkovito šire unutar lokalnih zajednica jer su članovi gusto povezani. Istovremeno, kratke globalne putanje omogućuju da informacija preskoči iz jedne zajednice u drugu putem malobrojnih prečaca. Ova kombinacija objašnjava zašto vijesti mogu brzo postati viralne, šireći se najprije unutar uskih krugova, a potom eksplodirajući na globalnu razinu kada dosegnu ključne mostove između zajednica.
```{r}
#| label: tbl-small-world
#| tbl-cap: "Usporedba strukturnih svojstava različitih tipova mreža. Mreže malog svijeta kombiniraju visoko klasteriranje pravilnih rešetki s kratkim putanjama nasumičnih mreža."
# tablica s usporedbom svojstava triju tipova mreža
sw_comparison <- data.frame(
Tip_mreze = c("Pravilna rešetka", "Mreža malog svijeta", "Nasumična mreža"),
Klasteriranje = c("Visoko", "Visoko", "Nisko"),
Prosjecna_putanja = c("Duga", "Kratka", "Kratka"),
Primjer = c(
"Geografski ograničene zajednice",
"Većina stvarnih društvenih mreža",
"Teoretski konstrukt"
),
Implikacije = c(
"Spora difuzija, lokalna kohezija",
"Brza difuzija uz lokalnu koheziju",
"Brza difuzija bez lokalne strukture"
)
)
# formatiranje tablice
kable(sw_comparison,
col.names = c("Tip mreže", "Klasteriranje", "Prosječna putanja", "Primjer", "Implikacije za komunikaciju")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Ključan uvid iz tablice jest da mreže malog svijeta kombiniraju prednosti pravilnih rešetki (lokalna kohezija) i nasumičnih mreža (kratke putanje), što ih čini iznimno učinkovitim strukturama za širenje informacija.
Empirijska istraživanja pokazala su da mnoge komunikacijske mreže doista pokazuju svojstva malog svijeta. Mreža pratitelja na Twitteru, mreža prijatelja na Facebooku, mreža citiranja akademskih radova i mreža hiperlinkova na webu sve pokazuju kombinaciju visokog klasteriranja i kratkih prosječnih putanja. Ovo svojstvo čini te sustave iznimno učinkovitima za širenje informacija, ali i ranjivima na brzo širenje dezinformacija koje mogu doseći milijune korisnika u rekordno kratkom vremenu.
Opisani fenomen malog svijeta govori o putanjama i klasteriranju u mrežama, no ne objašnjava zašto neke mreže pokazuju ekstremnu nejednakost u distribuciji veza, što je tema sljedećeg odjeljka.
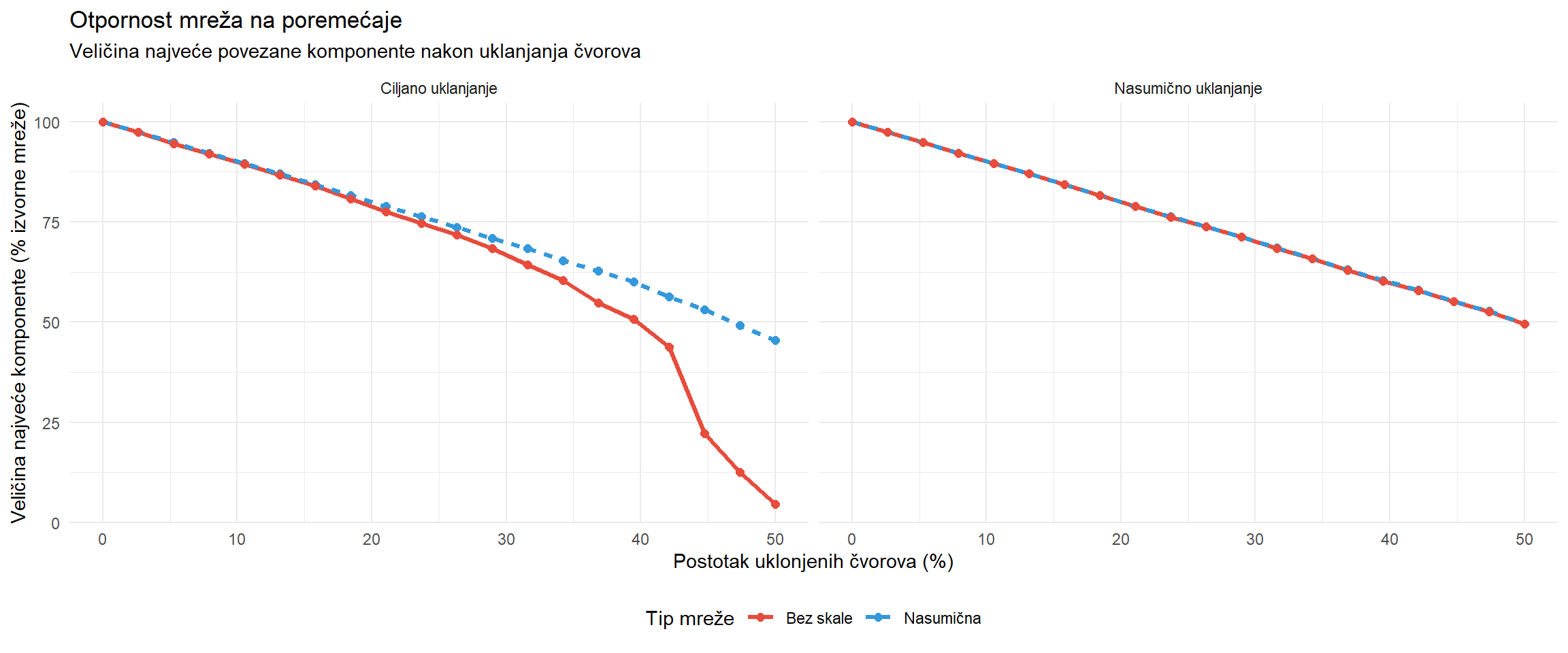
## Mreže bez skale
Dok fenomen malog svijeta opisuje globalna svojstva putanja i klasteriranja, **mreže bez skale** (engl. *scale-free networks*) odnose se na specifičnu distribuciju povezanosti čvorova. U mreži bez skale, distribucija stupnjeva slijedi **zakon potencije** (engl. *power law*):
$$P(k) \propto k^{-\gamma}$$
U ovoj formuli $P(k)$ označava vjerojatnost da nasumično odabrani čvor ima stupanj $k$, a $\gamma$ je eksponent zakona potencije koji tipično poprima vrijednosti između 2 i 3 za stvarne mreže. Ključna karakteristika ove distribucije jest da nema karakterističnu skalu, odnosno tipičnu vrijednost oko koje bi se stupnjevi koncentrirali. Umjesto toga, postoji kontinuum od čvorova s vrlo malo veza do rijetkih čvorova s enormno mnogo veza. Mreže bez skale generiraju se funkcijom `barabasi.game()` iz paketa `igraph` uz parametar `m` koji određuje broj veza koje svaki novi čvor stvara.
```{r}
#| label: fig-degree-distribution
#| fig-cap: "Usporedba distribucija stupnjeva za nasumičnu mrežu (lijevo) i mrežu bez skale (desno). Nasumična mreža pokazuje zvonoliku distribuciju s karakterističnim stupnjem, dok mreža bez skale pokazuje distribuciju zakona potencije s dugim repom visokih vrijednosti."
#| fig-width: 12
#| fig-height: 5
set.seed(42)
# generiranje nasumične mreže s 1000 čvorova
random_large <- erdos.renyi.game(1000, p = 0.01, type = "gnp")
# generiranje mreže bez skale s 1000 čvorova
scale_free_large <- barabasi.game(1000, m = 5, directed = FALSE)
# priprema podataka o stupnjevima za nasumičnu mrežu
random_degrees <- data.frame(
stupanj = degree(random_large),
tip = "Nasumična mreža\n(Erdos-Renyi)"
)
# priprema podataka o stupnjevima za mrežu bez skale
sf_degrees <- data.frame(
stupanj = degree(scale_free_large),
tip = "Mreža bez skale\n(Barabasi-Albert)"
)
all_degrees <- rbind(random_degrees, sf_degrees)
# histogram za nasumičnu mrežu
p1 <- ggplot(random_degrees, aes(x = stupanj)) +
geom_histogram(binwidth = 1, fill = "#3498db", color = "white", alpha = 0.8) +
labs(
title = "Nasumična mreža (Erdos-Renyi)",
subtitle = paste0("n = 1000, prosječni stupanj = ", round(mean(random_degrees$stupanj), 1)),
x = "Stupanj čvora",
y = "Frekvencija"
) +
theme_minimal(base_size = 11) +
geom_vline(xintercept = mean(random_degrees$stupanj), color = "#e74c3c",
linetype = "dashed", linewidth = 1)
# histogram za mrežu bez skale
p2 <- ggplot(sf_degrees, aes(x = stupanj)) +
geom_histogram(binwidth = 5, fill = "#e74c3c", color = "white", alpha = 0.8) +
labs(
title = "Mreža bez skale (Barabasi-Albert)",
subtitle = paste0("n = 1000, prosječni stupanj = ", round(mean(sf_degrees$stupanj), 1)),
x = "Stupanj čvora",
y = "Frekvencija"
) +
theme_minimal(base_size = 11) +
scale_x_continuous(limits = c(0, max(sf_degrees$stupanj)))
gridExtra::grid.arrange(p1, p2, ncol = 2)
```
Vizualno, razlika između nasumične mreže i mreže bez skale postaje očita kada se promotri distribucija stupnjeva. U nasumičnoj mreži većina čvorova ima približno jednak broj veza koji se grupira oko prosječne vrijednosti, tvoreći zvonoliku distribuciju. U mreži bez skale, većina čvorova ima vrlo malo veza dok mali broj čvorova, nazvanih **čvorištima** ili hubovima, ima enormno mnogo veza. Ova ekstremna nejednakost ključna je karakteristika mreža bez skale.
```{r}
#| label: fig-loglog-distribution
#| fig-cap: "Distribucija stupnjeva na logaritamskoj skali. Za mreže bez skale, log-log graf pokazuje približno linearni odnos što indicira zakon potencije. Nagib pravca odgovara eksponentu gama."
#| fig-width: 10
#| fig-height: 5
# izračun distribucije stupnjeva
sf_degree_dist <- data.frame(table(degree(scale_free_large)))
colnames(sf_degree_dist) <- c("stupanj", "frekvencija")
sf_degree_dist$stupanj <- as.numeric(as.character(sf_degree_dist$stupanj))
sf_degree_dist$frekvencija <- as.numeric(sf_degree_dist$frekvencija)
# pretvaranje u vjerojatnosti
sf_degree_dist$vjerojatnost <- sf_degree_dist$frekvencija / sum(sf_degree_dist$frekvencija)
# vizualizacija na log-log skali
ggplot(sf_degree_dist, aes(x = stupanj, y = vjerojatnost)) +
geom_point(color = "#e74c3c", size = 2, alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE, color = "#2c3e50", linetype = "dashed") +
scale_x_log10() +
scale_y_log10() +
labs(
title = "Distribucija stupnjeva na log-log skali",
subtitle = "Linearni odnos indicira zakon potencije karakterističan za mreže bez skale",
x = "Stupanj čvora (log skala)",
y = "Vjerojatnost (log skala)"
) +
theme_minimal(base_size = 12) +
annotate("text", x = 50, y = 0.01,
label = "Nagib = -gama", size = 4, color = "#2c3e50")
```
Barabasi i Albert 1999. godine predložili su mehanizam koji objašnjava kako mreže bez skale nastaju. Njihov model temelji se na dva ključna procesa: **rast** i **preferencijsko prikapčanje**. Mreža raste dodavanjem novih čvorova koji se povezuju s postojećim čvorovima. Ključna karakteristika jest da novi čvorovi ne biraju susjede nasumično već preferiraju povezivanje s već dobro povezanim čvorovima. Vjerojatnost da će novi čvor formirati vezu s postojećim čvorom $i$ proporcionalna je stupnju tog čvora:
$$\Pi(k_i) = \frac{k_i}{\sum_j k_j}$$
Ovaj mehanizam proizvodi dinamiku bogatiji postaju bogatiji gdje čvorovi koji su rano stekli prednost u broju veza nastavljaju privlačiti neproporcionalno više novih veza. Rezultat je ekstremna koncentracija veza u malom broju čvorišta.
```{r}
#| label: fig-preferential-attachment
#| fig-cap: "Vizualizacija mreže bez skale s 50 čvorova. Veličina čvora proporcionalna je stupnju. Jasno su vidljiva čvorišta (hubovi) s mnogo veza dok većina čvorova ima samo nekoliko poveznica."
#| fig-width: 9
#| fig-height: 7
set.seed(42)
# generiranje mreže bez skale s 50 čvorova
demo_sf <- barabasi.game(50, m = 2, directed = FALSE)
# izračun stupnja i identifikacija čvorišta
V(demo_sf)$degree <- degree(demo_sf)
V(demo_sf)$is_hub <- degree(demo_sf) > quantile(degree(demo_sf), 0.9)
# označavanje čvorišta crvenom bojom
node_colors <- ifelse(V(demo_sf)$is_hub, "#e74c3c", "#3498db")
plot(demo_sf,
layout = layout_with_fr,
vertex.size = sqrt(V(demo_sf)$degree) * 3 + 3,
vertex.color = node_colors,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 0.8,
main = "Mreža bez skale: čvorišta (crveno) vs. periferni čvorovi (plavo)")
legend("bottomleft",
legend = c("Čvorište (hub)", "Periferni čvor"),
fill = c("#e74c3c", "#3498db"),
bty = "n")
```
U kontekstu istraživanja masovne komunikacije, mreže bez skale imaju dalekosežne implikacije. Postojanje čvorišta znači da mali broj aktera ima disproporcionalan utjecaj na tokove informacija. U mreži dijeljenja vijesti na društvenim mrežama, nekoliko influencera s milijunima pratitelja može doseći više ljudi nego tisuće običnih korisnika zajedno. U mreži citiranja među medijima, nekoliko autoritativnih izvora dominira kao referentne točke dok većina medija ima marginalnu citiranost.
```{r}
#| label: tbl-scale-free-implications
#| tbl-cap: "Implikacije strukture mreže bez skale za masovnu komunikaciju. Postojanje čvorišta ima i pozitivne i negativne posljedice za komunikacijski ekosustav."
# tablica s implikacijama mreža bez skale za komunikacijski ekosustav
sf_implications <- data.frame(
Aspekt = c(
"Širenje informacija",
"Otpornost na greške",
"Ranjivost na napade",
"Koncentracija moći",
"Viralnost sadržaja"
),
Karakteristika = c(
"Čvorišta omogućuju brzo globalno širenje",
"Nasumično uklanjanje čvorova malo utječe na mrežu",
"Ciljano uklanjanje čvorišta može fragmentirati mrežu",
"Mali broj aktera kontrolira većinu tokova",
"Sadržaj koji dođe do čvorišta eksplodira"
),
Primjer_u_medijima = c(
"Vijest koju podijeli influencer doseže milijune",
"Gašenje malih portala ne utječe na ekosustav",
"Suspenzija glavnih računa dramatično utječe na diskurs",
"Nekoliko medijskih kuća postavlja agendu",
"Meme ili video postaje viralan preko ključnih računa"
)
)
# formatiranje tablice
kable(sf_implications,
col.names = c("Aspekt", "Karakteristika", "Primjer u medijima")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Tablica ilustrira dualnu prirodu mreža bez skale: ista struktura koja omogućuje brzo širenje informacija ujedno stvara ranjivosti i koncentraciju moći u rukama malog broja aktera.
Posebno zanimljiva karakteristika mreža bez skale jest njihova **asimetrična otpornost**. Ove mreže pokazuju izvanrednu otpornost na nasumične poremećaje jer uklanjanje nasumičnih čvorova uglavnom pogađa periferne čvorove s malo veza, što minimalno utječe na globalnu povezanost. Međutim, iste mreže izrazito su ranjive na ciljane napade usmjerene protiv čvorišta. Uklanjanje samo nekoliko najvažnijih čvorišta može fragmentirati mrežu u nepovezane komponente. Ova dualnost ima praktične implikacije za razumijevanje otpornosti komunikacijskih sustava i strategija za suzbijanje dezinformacija ili koordiniranih kampanja.
```{r}
#| label: fig-robustness
#| fig-cap: "Usporedba otpornosti nasumične mreže i mreže bez skale na dva tipa poremećaja. Lijevo: nasumično uklanjanje čvorova. Desno: ciljano uklanjanje čvorova s najviše veza. Mreže bez skale su robusne na nasumične greške ali ranjive na ciljane napade."
#| fig-width: 12
#| fig-height: 5
set.seed(42)
# funkcija za simulaciju otpornosti mreže na uklanjanje čvorova
simulate_robustness <- function(net, type = "random", steps = 20) {
n <- vcount(net)
removal_fractions <- seq(0, 0.5, length.out = steps)
results <- numeric(steps)
for (i in seq_along(removal_fractions)) {
temp_net <- net
n_remove <- floor(removal_fractions[i] * n)
if (n_remove > 0) {
if (type == "random") {
remove_nodes <- sample(V(temp_net), n_remove)
} else {
degrees <- degree(temp_net)
remove_nodes <- order(degrees, decreasing = TRUE)[1:n_remove]
}
temp_net <- delete_vertices(temp_net, remove_nodes)
}
if (vcount(temp_net) > 0) {
components <- components(temp_net)
results[i] <- max(components$csize) / vcount(net)
} else {
results[i] <- 0
}
}
return(data.frame(
uklonjeno = removal_fractions,
najveca_komponenta = results
))
}
# generiranje mreža za usporedbu otpornosti
random_net_rob <- erdos.renyi.game(500, p = 0.02, type = "gnp")
sf_net_rob <- barabasi.game(500, m = 5, directed = FALSE)
# simulacija četiri scenarija
random_random <- simulate_robustness(random_net_rob, "random")
random_random$mreza <- "Nasumična"
random_random$napad <- "Nasumično uklanjanje"
sf_random <- simulate_robustness(sf_net_rob, "random")
sf_random$mreza <- "Bez skale"
sf_random$napad <- "Nasumično uklanjanje"
random_targeted <- simulate_robustness(random_net_rob, "targeted")
random_targeted$mreza <- "Nasumična"
random_targeted$napad <- "Ciljano uklanjanje"
sf_targeted <- simulate_robustness(sf_net_rob, "targeted")
sf_targeted$mreza <- "Bez skale"
sf_targeted$napad <- "Ciljano uklanjanje"
# spajanje rezultata svih simulacija
all_robustness <- rbind(random_random, sf_random, random_targeted, sf_targeted)
ggplot(all_robustness, aes(x = uklonjeno * 100, y = najveca_komponenta * 100,
color = mreza, linetype = mreza)) +
geom_line(linewidth = 1.2) +
geom_point(size = 2) +
facet_wrap(~napad) +
scale_color_manual(values = c("Nasumična" = "#3498db", "Bez skale" = "#e74c3c")) +
labs(
title = "Otpornost mreža na poremećaje",
subtitle = "Veličina najveće povezane komponente nakon uklanjanja čvorova",
x = "Postotak uklonjenih čvorova (%)",
y = "Veličina najveće komponente (% izvorne mreže)",
color = "Tip mreže",
linetype = "Tip mreže"
) +
theme_minimal(base_size = 11) +
theme(legend.position = "bottom")
```
Empirijska istraživanja pokazala su da mnoge komunikacijske mreže doista pokazuju karakteristike mreža bez skale. Distribucija pratitelja na Twitteru, distribucija citiranosti znanstvenih radova, distribucija posjećenosti web stranica i distribucija dijeljenja vijesti sve pokazuju približno distribuciju zakona potencije. Ova univerzalnost sugerira da slični generativni procesi, poput preferencijskog prikapčanja, operiraju u raznolikim komunikacijskim sustavima. Razumijevanje ove strukture ključno je za dizajniranje intervencija, bilo da je cilj maksimizirati doseg poruke identificiranjem ključnih čvorišta ili minimizirati širenje dezinformacija prepoznavanjem i neutraliziranjem ključnih širitelja.
```{r}
#| label: tbl-macro-summary
#| tbl-cap: "Sažetak mjera strukture mreže na makro razini s njihovim interpretacijama u kontekstu istraživanja masovne komunikacije."
# sažetak svih makro mjera mrežne strukture
macro_summary <- data.frame(
Mjera = c("Gustoća", "Koeficijent klasteriranja", "Prosječna duljina putanje", "Eksponent zakona potencije (gama)"),
Definicija = c(
"Udio realiziranih veza od mogućih",
"Vjerojatnost da su susjedi čvora međusobno povezani",
"Prosječan broj koraka između bilo koja dva čvora",
"Nagib distribucije stupnjeva na log-log skali"
),
Tipicne_vrijednosti = c(
"0.001 - 0.3 ovisno o veličini",
"0.1 - 0.5 za društvene mreže",
"3 - 8 za većinu stvarnih mreža",
"2 - 3 za mreže bez skale"
),
Interpretacija = c(
"Kohezivnost i integriranost zajednice",
"Lokalna struktura zajednica i klika",
"Učinkovitost globalne komunikacije",
"Stupanj nejednakosti u distribuciji veza"
)
)
# formatiranje tablice
kable(macro_summary,
col.names = c("Mjera", "Definicija", "Tipične vrijednosti", "Interpretacija")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Zajednički, ove četiri mjere pružaju sveobuhvatan profil makro strukture komunikacijske mreže i omogućuju sustavnu usporedbu različitih komunikacijskih ekosustava.
Razumijevanje makro strukture mreže pruža temelj za sofisticiraniju analizu komunikacijskih fenomena. Gustoća govori o kohezivnosti sustava, fenomen malog svijeta objašnjava kako se informacije mogu brzo širiti usprkos velikoj veličini mreže, a distribucija zakona potencije otkriva ekstremnu koncentraciju utjecaja u malom broju čvorišta. Ova tri koncepta zajedno pružaju bogat okvir za razumijevanje arhitekture suvremenih komunikacijskih ekosustava i procesa koji se unutar njih odvijaju.
Makro mjere opisuju mrežu kao cjelinu, no istovremeno ostavljaju otvoreno pitanje unutarnje organizacije: formiraju li se unutar mreže prepoznatljive skupine i, ako da, po kojim principima? Upravo je to tema sljedećeg poglavlja koje razmatra grupe, klastere i zajednice.
# Grupe, klasteri i zajednice
Zamislimo istraživača koji analizira mrežu interakcija na hrvatskom političkom Twitteru tijekom predizborne kampanje. Vizualizirajući mrežu, primjećuje da se korisnici ne raspoređuju nasumično već formiraju jasno odvojene skupine. Korisnici unutar svake skupine intenzivno komuniciraju međusobno, dijele slične sadržaje i retweetaju jedni druge, dok su interakcije između skupina znatno rjeđe. Daljnjom analizom otkriva da ove skupine odgovaraju političkim preferencijama: birači jedne stranke grupiraju se zajedno, odvojeni od birača konkurentskih stranaka. Ova opservacija otvara fundamentalna pitanja o strukturi komunikacijskih mreža: zašto se formiraju grupe, kako ih je moguće identificirati i kvantificirati, te koje su posljedice takve fragmentacije za javni diskurs?
Analiza grupa, klastera i zajednica unutar mreža predstavlja jedno od najaktivnijih područja mrežne znanosti s dalekosežnim implikacijama za razumijevanje društvenih fenomena. Ljudi imaju prirodnu tendenciju formiranja skupina s onima koji su im slični, bilo po demografskim karakteristikama, interesima, uvjerenjima ili geografskoj blizini. Ova tendencija, poznata kao homofilija, rezultira mrežnim strukturama koje su daleko od nasumičnih. Razumijevanje ovih struktura omogućuje uvide u procese poput formiranja javnog mnijenja, širenja informacija unutar i između zajednica, polarizacije diskursa i fragmentacije javne sfere. U ovom odjeljku razmatraju se ključni koncepti i metode za analizu grupne strukture mreža, počevši od najjednostavnijih potpuno povezanih podgrupa (klika), preko fenomena homofilije, do sofisticiranih algoritama za detekciju zajednica i teorije strukturnih rupa. Koncepti poput homofilije i polarizacije povezuju se s komunikološkim teorijama poput spirale šutnje i selektivne izloženosti medijima, čime mrežna analiza nadopunjuje klasične pristupe analizi sadržaja obrađene u poglavlju 5.
```{r}
#| label: setup-section5
#| include: false
# učitavanje paketa za mrežnu analizu i vizualizaciju
library(igraph) # temeljni paket za analizu mreža
library(ggraph) # vizualizacija mreža temeljena na ggplot2
library(tidygraph) # manipulacija mrežnih podataka u tidy formatu
library(ggplot2) # vizualizacija podataka
library(dplyr) # manipulacija podataka
library(tidyr) # preoblikovanje podataka
library(knitr) # formatiranje tablica
library(kableExtra) # napredno formatiranje tablica
# postavljanje teme za vizualizacije
theme_set(theme_minimal(base_size = 12))
```
## Klike
**Klika** (engl. *clique*) predstavlja najjednostavniji i najstroži oblik grupne strukture u mreži. Formalno, klika je potpuni podgraf, odnosno skup čvorova u kojem je svaki čvor izravno povezan sa svakim drugim čvorom u tom skupu. U klici od tri čvora postoje tri veze, u klici od četiri čvora postoji šest veza, a općenito u klici od $k$ čvorova postoji $\frac{k(k-1)}{2}$ veza. Intuitivno, klika predstavlja savršeno kohezivnu grupu gdje svi članovi poznaju sve ostale članove. Klike se identificiraju funkcijom `cliques()` iz paketa `igraph`, pri čemu argumenti `min` i `max` određuju raspon veličina klika.
U kontekstu društvenih mreža, klike možemo zamisliti kao uske krugove prijatelja gdje je svaka osoba prijatelj sa svakom drugom osobom u grupi. U kontekstu istraživanja masovne komunikacije, klika bi mogla predstavljati grupu novinara koji svi međusobno surađuju, grupu portala koji svi međusobno citiraju ili grupu korisnika društvenih mreža koji svi međusobno prate i dijele sadržaje jedni drugih.
```{r}
#| label: fig-cliques-example
#| fig-cap: "Primjeri klika različitih veličina. Klika-3 (trokut) najčešći je oblik, klika-4 i klika-5 sve su rjeđe jer zahtijevaju sve gušću povezanost. U stvarnim mrežama, velike klike su izuzetno rijetke."
#| fig-width: 12
#| fig-height: 4
# postavljanje parametara za usporedni prikaz četiri klike
par(mfrow = c(1, 4), mar = c(2, 1, 3, 1))
# kreiranje i vizualizacija klike veličine 3
clique3 <- make_full_graph(3)
plot(clique3,
vertex.size = 35,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = c("A", "B", "C"),
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray40",
edge.width = 3,
main = "Klika-3 (Trokut)\n3 veze")
# kreiranje i vizualizacija klike veličine 4
clique4 <- make_full_graph(4)
plot(clique4,
vertex.size = 35,
vertex.color = "#2ecc71",
vertex.frame.color = NA,
vertex.label = c("A", "B", "C", "D"),
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray40",
edge.width = 3,
main = "Klika-4\n6 veza")
# kreiranje i vizualizacija klike veličine 5
clique5 <- make_full_graph(5)
plot(clique5,
vertex.size = 35,
vertex.color = "#e74c3c",
vertex.frame.color = NA,
vertex.label = c("A", "B", "C", "D", "E"),
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray40",
edge.width = 2.5,
main = "Klika-5\n10 veza")
# kreiranje i vizualizacija klike veličine 6
clique6 <- make_full_graph(6)
plot(clique6,
vertex.size = 30,
vertex.color = "#9b59b6",
vertex.frame.color = NA,
vertex.label = LETTERS[1:6],
vertex.label.color = "white",
vertex.label.cex = 1,
edge.color = "gray40",
edge.width = 2,
main = "Klika-6\n15 veza")
```
Identificiranje klika u mreži omogućuje otkrivanje najkohezivnijih podskupina. Međutim, strogi zahtjev da svaki član mora biti povezan sa svakim drugim članom čini velike klike izuzetno rijetkim u stvarnim mrežama. U velikoj društvenoj mreži od tisuću čvorova moguće je pronaći stotine trokuta (klika-3), desetke klika-4, možda nekoliko klika-5, a klike većih veličina vjerojatno neće postojati. Ova rijetkoća proizlazi iz kombinatoričkih ograničenja jer broj potrebnih veza eksponencijalno raste s veličinom klike.
```{r}
#| label: fig-cliques-in-network
#| fig-cap: "Identifikacija klika u primjeru mreže. Crveno su označene sve klike veličine 3 (trokuti). Svaki trokut predstavlja potpuno povezanu trojku čvorova, što indicira kohezivnu podgrupu."
#| fig-width: 9
#| fig-height: 7
set.seed(42)
# kreiranje primjera mreže za detekciju klika
example_net <- graph_from_literal(
A--B--C--A,
B--D--E--B,
C--D,
E--F--G--H--E,
F--H,
G--I--J--K--G,
I--K,
L--M--N--L,
M--O,
A--L
)
# pronalaženje svih klika veličine 3
cliques_3 <- cliques(example_net, min = 3, max = 3)
# označavanje bridova koji pripadaju klikama
edge_in_clique <- rep(FALSE, ecount(example_net))
for (cl in cliques_3) {
cl_nodes <- as.numeric(cl)
for (i in 1:(length(cl_nodes)-1)) {
for (j in (i+1):length(cl_nodes)) {
eid <- get.edge.ids(example_net, c(cl_nodes[i], cl_nodes[j]))
if (eid > 0) edge_in_clique[eid] <- TRUE
}
}
}
E(example_net)$color <- ifelse(edge_in_clique, "#e74c3c", "gray70")
E(example_net)$width <- ifelse(edge_in_clique, 3, 1.5)
# označavanje čvorova koji pripadaju klikama
node_in_clique <- rep(FALSE, vcount(example_net))
for (cl in cliques_3) {
node_in_clique[as.numeric(cl)] <- TRUE
}
V(example_net)$color <- ifelse(node_in_clique, "#e74c3c", "#3498db")
# vizualizacija mreže s označenim klikama
plot(example_net,
layout = layout_with_fr,
vertex.size = 25,
vertex.frame.color = NA,
vertex.label.color = "white",
vertex.label.cex = 1,
main = paste0("Mreža s označenim klikama-3\nPronađeno ", length(cliques_3), " trokuta"))
legend("bottomleft",
legend = c("Čvor u klici", "Čvor izvan klika", "Veza u klici", "Ostale veze"),
col = c("#e74c3c", "#3498db", "#e74c3c", "gray70"),
pch = c(16, 16, NA, NA),
lty = c(NA, NA, 1, 1),
lwd = c(NA, NA, 3, 1.5),
bty = "n")
```
Budući da su klike često prerestriktivan koncept, istraživači koriste relaksirane verzije poput **n-klana** (čvorovi udaljeni najviše n koraka), **k-plexa** (dopušta da svakom čvoru nedostaje do k veza) ili **k-jezgre** (svaki čvor ima najmanje k veza unutar podgrupa). Ove relaksirane definicije omogućuju identificiranje kohezivnih grupa koje nisu savršeno povezane, ali ipak pokazuju visoku razinu unutarnje gustoće.
```{r}
#| label: tbl-clique-variants
#| tbl-cap: "Usporedba strogog koncepta klike s relaksiranim varijantama koje dopuštaju manje savršenu povezanost unutar grupe."
# tablica s usporedbom strogog i relaksiranih koncepata kohezivnih grupa
clique_variants <- data.frame(
Koncept = c("Klika", "K-jezgra", "N-klan", "K-pleks"),
Definicija = c(
"Svaki čvor povezan sa svakim drugim",
"Svaki čvor ima najmanje k veza unutar grupe",
"Svi čvorovi udaljeni najviše n koraka",
"Svakom čvoru nedostaje najviše k veza do potpunosti"
),
Strogost = c("Najviša", "Srednja", "Niža", "Niža"),
Primjena = c(
"Identifikacija najužih krugova",
"Pronalaženje kohezivnih jezgri",
"Grupe s neizravnim vezama",
"Gotovo potpune grupe"
)
)
# formatiranje tablice
kable(clique_variants,
col.names = c("Koncept", "Definicija", "Strogost", "Tipična primjena")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Relaksirane varijante klika omogućuju istraživaču prilagodbu strogosti definicije kohezivne grupe ovisno o specifičnom istraživačkom pitanju i karakteristikama promatrane mreže.
Dok koncept klike opisuje potpunu povezanost unutar skupine, u stvarnim mrežama formiranje grupa često nije posljedica slučajnosti, već tendencije da se slični akteri međusobno povezuju. Upravo tu tendenciju opisuje fenomen homofilije.
## Homofilija
**Homofilija** (engl. *homophily*), doslovno ljubav prema sličnima, označava temeljnu tendenciju u društvenim mrežama da se veze formiraju češće između sličnih nego između različitih aktera. Ova tendencija sažeta je u poslovici ptice istog perja zajedno lete (engl. *birds of a feather flock together*). Homofilija može operirati po različitim dimenzijama sličnosti uključujući demografske karakteristike poput dobi, spola, etničke pripadnosti ili obrazovanja, geografsku blizinu, profesionalnu pripadnost, političke stavove ili kulturne preferencije. Homofilija se kvantificira funkcijom `assortativity_nominal()` iz paketa `igraph`.
U kontekstu istraživanja masovne komunikacije, homofilija ima dalekosežne implikacije. Ako se korisnici društvenih mreža pretežno povezuju s ideološki sličnim korisnicima, rezultat je fragmentirana mreža s izoliranim odjećnim komorama (engl. *echo chambers*) unutar kojih cirkuliraju slične informacije i perspektive. Ova struktura može pojačavati polarizaciju jer članovi svake komore rijetko dolaze u doticaj s alternativnim pogledima.
```{r}
#| label: fig-homophily
#| fig-cap: "Ilustracija homofilije u hipotetskoj mreži korisnika društvenih mreža. Boja označava političku orijentaciju (plavo = lijevo, crveno = desno). Vidljivo je da se veze pretežno formiraju unutar istih ideoloških skupina, dok su međugrupne veze rijetke."
#| fig-width: 10
#| fig-height: 7
set.seed(123)
# definiranje broja čvorova po skupini
n_left <- 15
n_right <- 15
# generiranje unutargrupnih mreža
left_net <- erdos.renyi.game(n_left, 0.4, type = "gnp")
right_net <- erdos.renyi.game(n_right, 0.4, type = "gnp")
# spajanje dviju grupa u jednu mrežu
combined_net <- disjoint_union(left_net, right_net)
# dodavanje malog broja međugrupnih veza
cross_edges <- sample(1:5, 1)
for (i in 1:cross_edges) {
from_node <- sample(1:n_left, 1)
to_node <- sample((n_left+1):(n_left+n_right), 1)
combined_net <- add_edges(combined_net, c(from_node, to_node))
}
V(combined_net)$political <- c(rep("Lijevo", n_left), rep("Desno", n_right))
V(combined_net)$color <- c(rep("#3498db", n_left), rep("#e74c3c", n_right))
# ručno postavljanje rasporeda za jasniju vizualizaciju
layout_matrix <- rbind(
cbind(runif(n_left, -2, -0.5), runif(n_left, -1, 1)),
cbind(runif(n_right, 0.5, 2), runif(n_right, -1, 1))
)
# označavanje međugrupnih veza narančastom bojom
E(combined_net)$color <- "gray60"
ends_matrix <- ends(combined_net, E(combined_net))
for (i in 1:ecount(combined_net)) {
from_pol <- V(combined_net)$political[ends_matrix[i, 1]]
to_pol <- V(combined_net)$political[ends_matrix[i, 2]]
if (from_pol != to_pol) {
E(combined_net)$color[i] <- "#f39c12"
}
}
plot(combined_net,
layout = layout_matrix,
vertex.size = 15,
vertex.frame.color = NA,
vertex.label = NA,
edge.width = 2,
main = "Homofilija u političkoj mreži: rijetke međugrupne veze")
legend("bottom",
legend = c("Lijeva orijentacija", "Desna orijentacija", "Međugrupna veza"),
col = c("#3498db", "#e74c3c", "#f39c12"),
pch = c(16, 16, NA),
lty = c(NA, NA, 1),
lwd = c(NA, NA, 2),
horiz = TRUE,
bty = "n")
```
Kvantificiranje homofilije zahtijeva usporedbu promatrane frekvencije veza između sličnih čvorova s očekivanom frekvencijom pod pretpostavkom nasumičnog formiranja veza. **Indeks homofilije** (ili asortativnost po atributu) mjeri stupanj u kojem čvorovi istog tipa imaju tendenciju povezivanja:
$$H = \frac{e_{ii} - a_i^2}{1 - a_i^2}$$
U ovoj formuli $e_{ii}$ predstavlja udio veza koje povezuju čvorove istog tipa $i$, a $a_i$ je udio čvorova tipa $i$ u mreži. Vrijednost 0 indicira nasumično miješanje, pozitivne vrijednosti indiciraju homofiliju, a negativne vrijednosti indiciraju heterofiliju (tendenciju povezivanja s različitima).
```{r}
#| label: fig-homophily-spectrum
#| fig-cap: "Spektar od heterofilije do homofilije. Lijevo: mreža s heterofilijom gdje se različite skupine pretežno povezuju međusobno. Sredina: nasumično miješanje bez preferencija. Desno: snažna homofilija s izoliranim skupinama."
#| fig-width: 12
#| fig-height: 4
set.seed(42)
# funkcija za generiranje mreža s kontroliranom razinom homofilije
create_mixed_network <- function(n_per_group, p_within, p_between) {
net <- make_empty_graph(n_per_group * 2, directed = FALSE)
V(net)$group <- rep(c("A", "B"), each = n_per_group)
# dodavanje unutargrupnih veza
for (i in 1:(n_per_group-1)) {
for (j in (i+1):n_per_group) {
if (runif(1) < p_within) {
net <- add_edges(net, c(i, j))
}
}
}
for (i in (n_per_group+1):(2*n_per_group-1)) {
for (j in (i+1):(2*n_per_group)) {
if (runif(1) < p_within) {
net <- add_edges(net, c(i, j))
}
}
}
# dodavanje međugrupnih veza
for (i in 1:n_per_group) {
for (j in (n_per_group+1):(2*n_per_group)) {
if (runif(1) < p_between) {
net <- add_edges(net, c(i, j))
}
}
}
return(net)
}
# generiranje triju mreža s različitim razinama homofilije
heterophily_net <- create_mixed_network(10, 0.1, 0.4)
random_net <- create_mixed_network(10, 0.25, 0.25)
homophily_net <- create_mixed_network(10, 0.5, 0.05)
V(heterophily_net)$color <- ifelse(V(heterophily_net)$group == "A", "#3498db", "#e74c3c")
V(random_net)$color <- ifelse(V(random_net)$group == "A", "#3498db", "#e74c3c")
V(homophily_net)$color <- ifelse(V(homophily_net)$group == "A", "#3498db", "#e74c3c")
par(mfrow = c(1, 3), mar = c(2, 1, 3, 1))
plot(heterophily_net,
vertex.size = 15,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray50",
edge.width = 1.5,
main = "Heterofilija\n(preferencija različitih)")
plot(random_net,
vertex.size = 15,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray50",
edge.width = 1.5,
main = "Nasumično miješanje\n(bez preferencija)")
plot(homophily_net,
vertex.size = 15,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray50",
edge.width = 1.5,
main = "Homofilija\n(preferencija sličnih)")
```
U istraživanjima masovne komunikacije, homofilija se manifestira na više razina. Na razini pojedinaca, korisnici društvenih mreža tendiraju pratiti i dijeliti sadržaje od korisnika sličnih političkih uvjerenja. Na razini medija, portali slične ideološke orijentacije češće citiraju jedni druge nego portale suprotne orijentacije. Na razini tema, rasprave o kontroverznim pitanjima često se fragmentiraju u odvojene struje koje rijetko komuniciraju. Razumijevanje homofilije ključno je za analizu fenomena poput polarizacije, odjećnih komora i selektivne izloženosti informacijama.
```{r}
#| label: tbl-homophily-types
#| tbl-cap: "Tipovi homofilije relevantni za istraživanja masovne komunikacije s primjerima i implikacijama."
# tablica s tipovima homofilije u komunikacijskim mrežama
homophily_types <- data.frame(
Dimenzija = c(
"Politička ideologija",
"Profesionalna pripadnost",
"Geografska lokacija",
"Generacija/dob",
"Jezična grupa"
),
Manifestacija = c(
"Praćenje ideološki bliskih izvora",
"Citiranje unutar struke",
"Dijeljenje lokalnih vijesti",
"Platformske preferencije po dobi",
"Konzumacija medija na materinjem jeziku"
),
Posljedice = c(
"Odjećne komore, polarizacija",
"Disciplinarna izolacija",
"Lokalizacija javne sfere",
"Generacijski jaz u informiranosti",
"Fragmentacija nacionalne javnosti"
),
Primjer = c(
"Ljevičari prate ljevičarske portale",
"Novinari citiraju novinare",
"Splićani dijele splitske vijesti",
"Mladi na TikToku, stariji na FB",
"Manjine prate medije na svom jeziku"
)
)
# formatiranje tablice
kable(homophily_types,
col.names = c("Dimenzija", "Manifestacija", "Posljedice", "Primjer")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Tablica pokazuje da homofilija u komunikacijskim mrežama operira istovremeno na više dimenzija, što može kumulativno pojačavati fragmentaciju javne sfere.
Dok homofilija opisuje tendencije formiranja veza po sličnosti, sljedeći odjeljak predstavlja opće metode za identificiranje grupa čvorova unutar mreže neovisno o unaprijed poznatim atributima.
## Modularnost i detekcija zajednica
Dok klike zahtijevaju savršenu povezanost, a homofilija opisuje tendencije formiranja veza, **detekcija zajednica** (engl. *community detection*) predstavlja opći problem identificiranja grupa čvorova koje su interno gusto povezane, a međusobno rijetko povezane. Ovaj problem nema jedinstveno rješenje jer sama definicija zajednice nije strogo određena. Različiti algoritmi operacionaliziraju koncept zajednice na različite načine, proizvodeći različite podjele iste mreže. Detekcija zajednica provodi se funkcijama `cluster_louvain()`, `cluster_walktrap()`, `cluster_label_prop()` i `cluster_infomap()` iz paketa `igraph`.
**Modularnost** (engl. *modularity*) jest mjera kvalitete podjele mreže na zajednice koja uspoređuje promatranu gustoću veza unutar zajednica s očekivanom gustoćom pod pretpostavkom nasumičnog formiranja veza. Formalno, modularnost se definira kao:
$$Q = \frac{1}{2m} \sum_{ij} \left[ A_{ij} - \frac{k_i k_j}{2m} \right] \delta(c_i, c_j)$$
U ovoj formuli $A_{ij}$ je element matrice susjedstva, $k_i$ i $k_j$ su stupnjevi čvorova $i$ i $j$, $m$ je ukupan broj veza, a $\delta(c_i, c_j)$ je Kroneckerova delta koja iznosi 1 ako čvorovi $i$ i $j$ pripadaju istoj zajednici, inače 0. Visoka modularnost (tipično iznad 0.3) indicira jasnu podjelu na zajednice.
```{r}
#| label: fig-community-detection
#| fig-cap: "Primjer detekcije zajednica pomoću Louvain algoritma na sintetičkoj mreži. Različite boje označavaju identificirane zajednice. Vidljiva je jasna modularna struktura s gustim vezama unutar zajednica i rijetkim vezama između njih."
#| fig-width: 10
#| fig-height: 7
set.seed(42)
# generiranje sintetičke mreže s jasnom modularnom strukturom
community_net <- sample_islands(
islands.n = 4,
islands.size = 12,
islands.pin = 0.5,
n.inter = 4
)
# primjena Louvain algoritma za detekciju zajednica
louvain_communities <- cluster_louvain(community_net)
# dodjela boja prema zajednicama
community_colors <- c("#3498db", "#e74c3c", "#2ecc71", "#9b59b6")
V(community_net)$community <- membership(louvain_communities)
V(community_net)$color <- community_colors[V(community_net)$community]
# izračun modularnosti
modularity_score <- modularity(louvain_communities)
# vizualizacija mreže s označenim zajednicama
plot(community_net,
layout = layout_with_fr,
vertex.size = 12,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1,
main = paste0("Detekcija zajednica (Louvain algoritam)\n",
"Pronađeno ", max(membership(louvain_communities)), " zajednice, ",
"Modularnost Q = ", round(modularity_score, 3)))
legend("bottomleft",
legend = paste("Zajednica", 1:4),
fill = community_colors,
bty = "n",
title = "Identificirane zajednice")
```
**Louvain algoritam** predstavlja jedan od najpopularnijih pristupa detekciji zajednica zbog svoje učinkovitosti i kvalitete rezultata. Algoritam radi u dvije faze koje se iterativno ponavljaju. U prvoj fazi, svaki čvor započinje kao zasebna zajednica, a zatim se iterativno premješta u zajednicu susjeda koja maksimalno povećava modularnost. U drugoj fazi, identificirane zajednice agregiraju se u super-čvorove, formirajući novu, manju mrežu na kojoj se postupak ponavlja. Algoritam konvergira kada više nije moguće povećati modularnost premještanjem čvorova.
```{r}
#| label: fig-louvain-steps
#| fig-cap: "Konceptualna ilustracija Louvain algoritma. Algoritam iterativno optimizira modularnost premještajući čvorove između zajednica, a zatim agregira zajednice u super-čvorove za sljedeću razinu analize."
#| fig-width: 12
#| fig-height: 4
set.seed(42)
# korak 1: svaki čvor zasebna zajednica
step1_net <- make_graph(~ A-B-C-A, D-E-F-D, G-H-I-G, A-D, D-G)
V(step1_net)$color <- rainbow(9)
# korak 2: optimizacija modularnosti - čvorovi grupirani
step2_net <- make_graph(~ A-B-C-A, D-E-F-D, G-H-I-G, A-D, D-G)
V(step2_net)$color <- c(rep("#3498db", 3), rep("#e74c3c", 3), rep("#2ecc71", 3))
# korak 3: agregacija u super-čvorove
step3_net <- make_graph(~ X-Y-Z, X-Y)
V(step3_net)$color <- c("#3498db", "#e74c3c", "#2ecc71")
par(mfrow = c(1, 3), mar = c(2, 1, 4, 1))
plot(step1_net,
vertex.size = 30,
vertex.frame.color = NA,
vertex.label.color = "white",
vertex.label.cex = 1,
edge.color = "gray40",
edge.width = 2,
main = "Korak 1:\nSvaki čvor zasebna zajednica")
plot(step2_net,
vertex.size = 30,
vertex.frame.color = NA,
vertex.label.color = "white",
vertex.label.cex = 1,
edge.color = "gray40",
edge.width = 2,
main = "Korak 2:\nOptimizacija modularnosti")
plot(step3_net,
vertex.size = 50,
vertex.frame.color = NA,
vertex.label = c("Z1", "Z2", "Z3"),
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray40",
edge.width = 3,
main = "Korak 3:\nAgregacija u super-čvorove")
```
```{r}
#| label: fig-community-comparison
#| fig-cap: "Usporedba rezultata različitih algoritama za detekciju zajednica na istoj mreži. Različiti algoritmi mogu proizvesti različite podjele ovisno o svojim pretpostavkama i ciljevima optimizacije."
#| fig-width: 12
#| fig-height: 8
set.seed(42)
# generiranje sintetičke mreže za usporedbu algoritama
comparison_net <- sample_islands(
islands.n = 3,
islands.size = 15,
islands.pin = 0.4,
n.inter = 6
)
# primjena četiri različita algoritma za detekciju zajednica
louvain_comm <- cluster_louvain(comparison_net)
walktrap_comm <- cluster_walktrap(comparison_net)
label_prop_comm <- cluster_label_prop(comparison_net)
infomap_comm <- cluster_infomap(comparison_net)
# zajednički raspored za usporedivost
par(mfrow = c(2, 2), mar = c(2, 1, 3, 1))
set.seed(42)
layout_coords <- layout_with_fr(comparison_net)
# vizualizacija rezultata svakog algoritma
plot(comparison_net,
layout = layout_coords,
vertex.size = 10,
vertex.color = membership(louvain_comm),
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.4),
main = paste0("Louvain\nQ = ", round(modularity(louvain_comm), 3),
", ", max(membership(louvain_comm)), " zajednica"))
plot(comparison_net,
layout = layout_coords,
vertex.size = 10,
vertex.color = membership(walktrap_comm),
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.4),
main = paste0("Walktrap\nQ = ", round(modularity(walktrap_comm), 3),
", ", max(membership(walktrap_comm)), " zajednica"))
plot(comparison_net,
layout = layout_coords,
vertex.size = 10,
vertex.color = membership(label_prop_comm),
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.4),
main = paste0("Label Propagation\nQ = ", round(modularity(label_prop_comm), 3),
", ", max(membership(label_prop_comm)), " zajednica"))
plot(comparison_net,
layout = layout_coords,
vertex.size = 10,
vertex.color = membership(infomap_comm),
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.4),
main = paste0("Infomap\nQ = ", round(modularity(infomap_comm), 3),
", ", max(membership(infomap_comm)), " zajednica"))
```
```{r}
#| label: tbl-community-algorithms
#| tbl-cap: "Pregled popularnih algoritama za detekciju zajednica s njihovim karakteristikama i tipičnim primjenama."
# tablica s pregledom algoritama za detekciju zajednica
community_algorithms <- data.frame(
Algoritam = c("Louvain", "Walktrap", "Label Propagation", "Infomap", "Girvan-Newman"),
Princip = c(
"Pohlepna optimizacija modularnosti",
"Nasumične šetnje unutar zajednica",
"Propagacija oznaka među susjedima",
"Minimizacija duljine opisa toka",
"Iterativno uklanjanje mostova"
),
Prednosti = c(
"Brz, skalabilan, dobri rezultati",
"Teoretski utemeljen, hijerarhijski",
"Vrlo brz, jednostavan",
"Hvata tokove informacija",
"Otkriva hijerarhijsku strukturu"
),
Nedostaci = c(
"Može propustiti male zajednice",
"Sporiji za velike mreže",
"Nedeterministički rezultati",
"Osjetljiv na parametre",
"Računalno zahtjevan"
)
)
# formatiranje tablice
kable(community_algorithms,
col.names = c("Algoritam", "Princip rada", "Prednosti", "Nedostaci")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Izbor algoritma za detekciju zajednica treba biti vođen karakteristikama mreže i istraživačkim pitanjem, a u praksi je preporučljivo primijeniti više algoritama i usporediti rezultate.
U kontekstu istraživanja masovne komunikacije, detekcija zajednica omogućuje mapiranje strukture javne sfere. Analizom mreže dijeljenja vijesti na društvenim mrežama moguće je identificirati ideološke skupine, tematske zajednice ili regionalne klastere. Analizom mreže citiranja među medijima moguće je otkriti medijske ekosustave i razumjeti kako se grupiraju izvori informacija. Ova saznanja imaju praktične implikacije za razumijevanje fragmentacije javnosti, ciljanje komunikacijskih kampanja i dizajn intervencija protiv dezinformacija. Pritom valja napomenuti da se rezultati mrežne analize mogu učinkovito kombinirati s metodama računalne analize teksta (v. poglavlje 11), primjerice identificiranjem tematskih razlika između mrežno detektiranih zajednica.
Detekcija zajednica identificira koji čvorovi pripadaju istim skupinama, no ne objašnjava ulogu aktera koji se nalaze između skupina. Upravo na te aktere usmjerena je teorija strukturnih rupa.
## Strukturne rupe
Dok se dosadašnja rasprava fokusirala na kohezivne grupe i njihovu unutarnju strukturu, teorija **strukturnih rupa** (engl. *structural holes*), koju je razvio sociolog Ronald Burt, usmjerava pažnju na praznine između grupa i aktere koji ih premošćuju. Strukturna rupa jest odsutnost veze između dvaju čvorova ili klastera koji bi inače bili nepovezani. Akter koji premošćuje strukturnu rupu, povezujući inače nepovezane dijelove mreže, zauzima strateški privilegiranu poziciju koja mu pruža pristup raznolikim informacijama i mogućnost posredovanja između različitih grupa.
Burtova teorija temelji se na ideji da redundantne veze, odnosno veze s čvorovima koji su i sami međusobno povezani, pružaju manje koristi od veza koje premošćuju strukturne rupe. Ako su svi prijatelji neke osobe ujedno i prijatelji jedni s drugima, informacije koje ta osoba dobije od bilo kojeg od njih vjerojatno će biti slične jer cirkuliraju unutar iste zatvorene grupe. Nasuprot tome, ako osoba ima prijatelje u različitim, nepovezanim grupama, svaki od njih pruža pristup jedinstvenim izvorima informacija.
```{r}
#| label: fig-structural-holes
#| fig-cap: "Ilustracija koncepta strukturnih rupa. Čvor E (označen zlatno) premošćuje strukturnu rupu između dva klastera, zauzimajući posredničku poziciju. Crvene isprekidane linije označavaju potencijalne veze koje bi eliminirale strukturnu rupu."
#| fig-width: 10
#| fig-height: 7
set.seed(42)
# kreiranje mreže s dva klastera i jednim posrednikom
sh_net <- graph_from_literal(
A--B--C--A,
A--D, B--D, C--D,
E,
F--G--H--F,
F--I, G--I, H--I,
D--E, E--F
)
# označavanje brokera i klastera
V(sh_net)$is_broker <- V(sh_net)$name == "E"
V(sh_net)$cluster <- c(rep(1, 4), 0, rep(2, 4))
# definiranje boja prema ulozi u mreži
node_colors <- case_when(
V(sh_net)$name == "E" ~ "#f1c40f",
V(sh_net)$cluster == 1 ~ "#3498db",
V(sh_net)$cluster == 2 ~ "#e74c3c"
)
# ručno postavljanje rasporeda za jasniju vizualizaciju
layout_sh <- matrix(c(
-2, 1,
-1, 2,
-1, 0,
-1, 1,
0, 1,
1, 1,
2, 2,
2, 0,
1, 1.5
), ncol = 2, byrow = TRUE)
plot(sh_net,
layout = layout_sh,
vertex.size = 30,
vertex.color = node_colors,
vertex.frame.color = "white",
vertex.frame.width = 2,
vertex.label.color = "white",
vertex.label.cex = 1.2,
edge.color = "gray40",
edge.width = 2.5,
main = "Strukturna rupa: E kao posrednik između klastera")
segments(x0 = -0.3, y0 = 0.5, x1 = 0.3, y1 = 0.5,
col = "#e74c3c", lty = 2, lwd = 2)
segments(x0 = -0.3, y0 = 1.5, x1 = 0.3, y1 = 1.5,
col = "#e74c3c", lty = 2, lwd = 2)
legend("bottomleft",
legend = c("Posrednik (Broker)", "Klaster 1", "Klaster 2", "Strukturna rupa"),
col = c("#f1c40f", "#3498db", "#e74c3c", "#e74c3c"),
pch = c(16, 16, 16, NA),
lty = c(NA, NA, NA, 2),
lwd = c(NA, NA, NA, 2),
bty = "n")
```
Za kvantificiranje pozicije aktera u odnosu na strukturne rupe, Burt je predložio mjeru **ograničenja** (engl. *constraint*) koja mjeri stupanj u kojem su veze aktera redundantne. Nisko ograničenje indicira da akter ima veze prema nepovezanim dijelovima mreže, dok visoko ograničenje indicira da su kontakti aktera međusobno povezani. Formalno, ograničenje čvora $i$ definira se kao:
$$C_i = \sum_j \left( p_{ij} + \sum_q p_{iq} p_{qj} \right)^2$$
gdje $p_{ij}$ predstavlja udio veze s čvorom $j$ u ukupnim vezama čvora $i$. Čvorovi s niskim ograničenjem zauzimaju pozicije brokera koji premošćuju strukturne rupe. Drugim riječima, ograničenje mjeri koliko su kontakti nekog aktera međusobno isprepleteni; ako su svi kontakti međusobno povezani, ograničenje je visoko i akter nema pristup raznolikim izvorima informacija, dok nisko ograničenje indicira da akter premošćuje praznine između nepovezanih skupina. Burtovo ograničenje izračunava se funkcijom `constraint()` iz paketa `igraph`.
```{r}
#| label: fig-constraint-visualization
#| fig-cap: "Vizualizacija Burtovog ograničenja (constraint) u mreži. Veličina čvora obrnuto je proporcionalna ograničenju - veći čvorovi imaju manje ograničenje i zauzimaju posredničke pozicije. Manji čvorovi imaju visoko ograničenje jer su uklopljeni u kohezivne grupe."
#| fig-width: 10
#| fig-height: 7
set.seed(42)
# generiranje mreže s jasnom klasterskom strukturom
broker_net <- sample_islands(
islands.n = 3,
islands.size = 8,
islands.pin = 0.6,
n.inter = 2
)
# izračun Burtovog ograničenja za svaki čvor
constraint_values <- constraint(broker_net)
# invertiranje ograničenja za vizualizaciju (veći čvor = manje ograničenje)
inv_constraint <- 1 / (constraint_values + 0.1)
node_size <- scales::rescale(inv_constraint, to = c(8, 25))
V(broker_net)$constraint <- constraint_values
V(broker_net)$is_broker <- constraint_values < median(constraint_values)
# brokeri označeni zlatnom bojom
node_colors <- ifelse(V(broker_net)$is_broker, "#f1c40f", "#3498db")
plot(broker_net,
layout = layout_with_fr,
vertex.size = node_size,
vertex.color = node_colors,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1.5,
main = "Burtovo ograničenje: brokeri (zlatno) vs. uklopljeni čvorovi (plavo)\nVeći čvor = manje ograničenje = više strukturnih rupa")
legend("bottomleft",
legend = c("Broker (nisko ograničenje)", "Uklopljen čvor (visoko ograničenje)"),
fill = c("#f1c40f", "#3498db"),
bty = "n")
```
```{r}
#| label: tbl-constraint-examples
#| tbl-cap: "Primjeri aktera s niskim i visokim ograničenjem u kontekstu medijskih istraživanja i njihove strateške implikacije."
# tablica s primjerima niskog i visokog ograničenja u medijskom kontekstu
constraint_examples <- data.frame(
Karakteristika = c(
"Nisko ograničenje (broker)",
"Visoko ograničenje (uklopljen)"
),
Pozicija_u_mrezi = c(
"Povezuje nepovezane grupe",
"Uklopljen u kohezivnu grupu"
),
Pristup_informacijama = c(
"Raznolike, neredundantne informacije",
"Redundantne informacije iz iste grupe"
),
Primjer_u_medijima = c(
"Novinar s izvorima u različitim sektorima; agregator koji povezuje mainstream i alternativne medije",
"Novinar koji surađuje samo s kolegama iz iste redakcije; korisnik unutar odjećne komore"
),
Strateska_prednost = c(
"Kontrola toka informacija, pristup raznolikim perspektivama, posrednička moć",
"Povjerenje i solidarnost unutar grupe, ali ograničen pristup novim informacijama"
)
)
# formatiranje tablice
kable(constraint_examples,
col.names = c("Karakteristika", "Pozicija u mreži", "Pristup informacijama",
"Primjer u medijima", "Strateška prednost/nedostatak")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Tablica naglašava da pozicija brokera donosi strateške prednosti u pristupu informacijama, ali ujedno zahtijeva ulaganje u održavanje raznolikih kontakata.
U kontekstu istraživanja masovne komunikacije, teorija strukturnih rupa ima značajne implikacije. Novinari ili mediji koji premošćuju strukturne rupe imaju pristup raznolikijim izvorima i mogu posredovati između različitih segmenata javnosti. Influenceri koji povezuju ideološki različite zajednice igraju ključnu ulogu u potencijalnom premošćivanju polarizacije. S druge strane, identificiranje strukturnih rupa može pomoći u razumijevanju zašto određene informacije ne cirkuliraju između grupa i kako bi intervencije mogle poboljšati protok informacija.
```{r}
#| label: fig-groups-summary
#| fig-cap: "Sažetak ključnih koncepata grupne strukture mreža. Od najstrožih (klike) do najopćenitijih (zajednice), različiti koncepti hvataju različite aspekte grupiranja u mrežama."
#| fig-width: 12
#| fig-height: 4
# usporedni prikaz četiri koncepta grupne strukture
par(mfrow = c(1, 4), mar = c(2, 1, 4, 1))
# klika: potpuna povezanost
clique_demo <- make_full_graph(5)
plot(clique_demo,
vertex.size = 25,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "#3498db",
edge.width = 2,
main = "KLIKA\nPotpuna povezanost")
# homofilija: sličnost privlači
set.seed(1)
homophily_demo <- graph_from_literal(A-B-C-A, D-E-F-D, A-D)
V(homophily_demo)$color <- c(rep("#3498db", 3), rep("#e74c3c", 3))
plot(homophily_demo,
vertex.size = 25,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray40",
edge.width = 2,
main = "HOMOFILIJA\nSličnost privlači")
# zajednice: modularna struktura
set.seed(1)
community_demo <- sample_islands(2, 5, 0.7, 1)
comm <- cluster_louvain(community_demo)
plot(community_demo,
vertex.size = 18,
vertex.color = membership(comm),
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray40",
edge.width = 1.5,
main = "ZAJEDNICE\nModularna struktura")
# strukturne rupe: brokeri i praznine
broker_demo <- graph_from_literal(A-B-C-A, D-E-F-D, B-X-E)
V(broker_demo)$color <- c(rep("#3498db", 3), rep("#e74c3c", 3), "#f1c40f")
plot(broker_demo,
vertex.size = 25,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = "gray40",
edge.width = 2,
main = "STRUKTURNE RUPE\nBrokeri i praznine")
```
Razumijevanje grupne strukture mreža pruža temelj za sofisticirane analize komunikacijskih fenomena. Identificiranje klika otkriva najuže krugove intenzivne suradnje. Mjerenje homofilije kvantificira tendencije formiranja veza po sličnosti. Detekcija zajednica mapira globalnu strukturu javne sfere. Analiza strukturnih rupa identificira ključne posrednike koji kontroliraju tokove informacija. Zajedno, ovi koncepti čine bogat analitički arsenal za razumijevanje kako su komunikacijske mreže strukturirane i kakve su posljedice te strukture za procese poput širenja informacija, formiranja javnog mnijenja i fragmentacije diskursa.
Analiza grupne strukture otkriva koji čvorovi pripadaju istim zajednicama, no ostaje pitanje kako te strukture učinkovito vizualno prikazati, osobito kada mreža postane prevelika za jednostavnu preglednost. Upravo se tim izazovima bavi sljedeći odjeljak.
# Vizualizacija mreža
Vizualizacija predstavlja jedan od najsnažnijih aspekata analize društvenih mreža. Za razliku od tradicionalnih statističkih pristupa koji reduciraju složene strukture na numeričke pokazatelje, mrežna vizualizacija omogućuje istraživaču da doslovno vidi strukturu odnosa, identificira obrasce, uoči anomalije i komunicira nalaze na intuitivan način. Dobra vizualizacija može otkriti strukturne karakteristike koje bi ostale skrivene u tablicama brojeva, poput postojanja klastera, identificiranja centralnih aktera ili otkrivanja mostova između zajednica. Međutim, vizualizacija mreža daleko je od trivijalne zadaće. Smještanje desetaka, stotina ili tisuća čvorova i njihovih veza u dvodimenzionalni prostor na način koji je informativan, čitljiv i estetski ugodan predstavlja značajan tehnički i konceptualni izazov.
U ovom odjeljku razmatraju se temeljni principi i praktični aspekti vizualizacije mreža. Započinje se algoritmima rasporeda koji određuju položaje čvorova u prostoru, s posebnim fokusom na pristupe temeljene na silama koji dominiraju suvremenom praksom. Potom se analizira problem preopterećenosti, poznat kao efekt dlakave lopte, koji nastaje kada mreža postane prevelika ili pregusta za smislenu vizualizaciju. Odjeljak zaključuje primjerom sofisticirane vizualizacije koja integrira informacije o centralnosti i zajednicama u jedinstven grafički prikaz.
```{r}
#| label: setup-section6
#| include: false
# učitavanje paketa za mrežnu analizu i vizualizaciju
library(igraph) # temeljni paket za analizu mreža
library(ggraph) # vizualizacija mreža temeljena na ggplot2
library(tidygraph) # manipulacija mrežnih podataka u tidy formatu
library(ggplot2) # vizualizacija podataka
library(dplyr) # manipulacija podataka
library(tidyr) # preoblikovanje podataka
library(knitr) # formatiranje tablica
library(kableExtra) # napredno formatiranje tablica
# postavljanje teme za vizualizacije
theme_set(theme_minimal(base_size = 12))
```
## Algoritmi rasporeda
Problem rasporeda mreže (engl. *graph layout*) svodi se na pitanje kako dodijeliti koordinate svakom čvoru u dvodimenzionalnom (ili trodimenzionalnom) prostoru tako da rezultirajuća vizualizacija bude informativna i čitljiva. Budući da mreža sama po sebi ne sadrži prostorne informacije, odnosno čvorovi nemaju inherentne koordinate, algoritam rasporeda mora te koordinate konstruirati na temelju topoloških svojstava mreže. Idealan raspored trebao bi smjestiti blisko povezane čvorove blizu jedni drugima, jasno razdvojiti različite klastere, minimizirati preklapanje veza i stvoriti vizualno uravnoteženu sliku. Algoritmi rasporeda dostupni su kao funkcije `layout_with_fr()` (Fruchterman-Reingold), `layout_with_kk()` (Kamada-Kawai), `layout_with_drl()` (DrL) i `layout_in_circle()` iz paketa `igraph`.
Najutjecajnija obitelj algoritama za raspored mreža temelji se na **fizikalnoj analogiji sila** (engl. *force-directed layout*). Ovi algoritmi tretiraju mrežu kao fizički sustav u kojem čvorovi djeluju poput nabijenih čestica koje se međusobno odbijaju, dok veze djeluju poput opruga koje privlače povezane čvorove.
```{r}
#| label: fig-layout-comparison
#| fig-cap: "Usporedba različitih algoritama rasporeda na istoj mreži. Fruchterman-Reingold i Kamada-Kawai jasno razdvajaju klastere, kružni raspored pokazuje modularnost, a zvjezdasti naglašava centralnost jednog čvora."
#| fig-width: 12
#| fig-height: 8
set.seed(42)
# generiranje sintetičke mreže za usporedbu rasporeda
comparison_net <- sample_islands(
islands.n = 3,
islands.size = 12,
islands.pin = 0.4,
n.inter = 3
)
# detekcija zajednica za označavanje bojom
communities <- cluster_louvain(comparison_net)
V(comparison_net)$community <- membership(communities)
# usporedni prikaz šest algoritama rasporeda
par(mfrow = c(2, 3), mar = c(1, 1, 3, 1))
plot(comparison_net,
layout = layout_with_fr,
vertex.size = 10,
vertex.color = V(comparison_net)$community,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1,
main = "Fruchterman-Reingold")
plot(comparison_net,
layout = layout_with_kk,
vertex.size = 10,
vertex.color = V(comparison_net)$community,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1,
main = "Kamada-Kawai")
plot(comparison_net,
layout = layout_with_drl,
vertex.size = 10,
vertex.color = V(comparison_net)$community,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1,
main = "DrL (Distributed Recursive)")
plot(comparison_net,
layout = layout_in_circle,
vertex.size = 10,
vertex.color = V(comparison_net)$community,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1,
main = "Kružni raspored")
plot(comparison_net,
layout = layout_as_star,
vertex.size = 10,
vertex.color = V(comparison_net)$community,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1,
main = "Zvjezdasti raspored")
plot(comparison_net,
layout = layout_with_graphopt,
vertex.size = 10,
vertex.color = V(comparison_net)$community,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1,
main = "GraphOpt")
```
Izbor algoritma rasporeda ovisi o karakteristikama mreže i ciljevima vizualizacije. Za mreže s jasnom klasterskom strukturom, algoritmi temeljeni na silama poput Fruchterman-Reingold ili Kamada-Kawai daju najbolje rezultate jer prirodno razdvajaju klastere. Za vrlo velike mreže, DrL algoritam je učinkovitiji jer je dizajniran za rad s mrežama od desetaka tisuća čvorova. Kružni raspored koristan je kada je cilj naglasiti modularnost mreže ili kada se čvorovi žele rasporediti prema nekom atributu poput kronološkog redoslijeda.
## Problem dlakave lopte
Kako broj čvorova i veza u mreži raste, vizualizacija postaje sve izazovnija. Ovaj fenomen naziva se **efekt dlakave lopte** (engl. *hairball effect*) jer vizualizacija velikih mreža postaje nerazlučiva masa veza iz koje je nemoguće iščitati strukturne informacije. Problem nastaje jer klasični algoritmi rasporeda temeljeni na silama pokušavaju smjestiti sve čvorove i veze u isti prostor, što s porastom broja elemenata neizbježno dovodi do vizualnog preopterećenja.
```{r}
#| label: fig-hairball-progression
#| fig-cap: "Progresija od čitljive do nečitljive vizualizacije s porastom veličine mreže. S 30 čvorova struktura je jasno vidljiva, sa 100 još prepoznatljiva, sa 300 počinje efekt dlakave lopte, a s 1000 čvorova vizualizacija postaje potpuno nečitljiva."
#| fig-width: 12
#| fig-height: 8
# usporedni prikaz vizualizacija za mreže rastućih veličina
par(mfrow = c(2, 2), mar = c(1, 1, 3, 1))
# mreža s 30 čvorova: jasno čitljiva
set.seed(42)
net_30 <- barabasi.game(30, m = 2, directed = FALSE)
plot(net_30,
layout = layout_with_fr,
vertex.size = 8,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray40", alpha = 0.6),
edge.width = 1,
main = "n = 30 čvorova\nStruktura jasno vidljiva")
# mreža sa 100 čvorova: još prepoznatljiva
set.seed(42)
net_100 <- barabasi.game(100, m = 2, directed = FALSE)
plot(net_100,
layout = layout_with_fr,
vertex.size = 5,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray40", alpha = 0.4),
edge.width = 0.5,
main = "n = 100 čvorova\nStruktura još prepoznatljiva")
# mreža s 300 čvorova: početak efekta dlakave lopte
set.seed(42)
net_300 <- barabasi.game(300, m = 2, directed = FALSE)
plot(net_300,
layout = layout_with_fr,
vertex.size = 3,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray40", alpha = 0.2),
edge.width = 0.3,
main = "n = 300 čvorova\nPočetak efekta dlakave lopte")
# mreža s 1000 čvorova: potpuna dlakava lopta
set.seed(42)
net_1000 <- barabasi.game(1000, m = 2, directed = FALSE)
plot(net_1000,
layout = layout_with_fr,
vertex.size = 1.5,
vertex.color = "#3498db",
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray40", alpha = 0.1),
edge.width = 0.2,
main = "n = 1000 čvorova\nPotpuna dlakava lopta")
```
Za suzbijanje efekta dlakave lopte primjenjuju se različite strategije, uključujući filtriranje slabih veza (prikazivanje samo veza iznad određenog praga težine), agregaciju čvorova po zajednicama (prikazivanje zajednica kao super-čvorova umjesto pojedinačnih aktera), korištenje transparentnosti i boje za naglašavanje relevantnih struktura, te interaktivnu eksploraciju pomoću specijaliziranih alata poput Gephija koji omogućuju zumiranje, filtriranje i dinamičku manipulaciju vizualizacijom.
## Primjer vizualizacije s ggraph
Sofisticirane vizualizacije mreža kombiniraju informacije o topološkoj strukturi s atributima čvorova i veza, omogućujući bogatiju komunikaciju nalaza. Paket `ggraph` omogućuje sofisticiranu vizualizaciju mreža koristeći gramatiku grafike poznatu iz paketa `ggplot2`. U sljedećem primjeru prikazana je vizualizacija sintetičke mreže u kojoj veličina čvora odražava stupanj centralnosti, boja označava pripadnost zajednici detektiranoj Louvain algoritmom, a oznake prikazuju samo najcentralnije čvorove kako bi se izbjeglo vizualno preopterećenje.
```{r}
#| label: fig-ggraph-demo
#| fig-cap: "Primjer sofisticirane vizualizacije mreže. Veličina čvora proporcionalna je stupnju centralnosti, boja označava zajednicu, a oznake prikazuju samo najcentralnije čvorove. Ovakva vizualizacija omogućuje istovremeno sagledavanje globalnog obrasca grupiranja i identifikaciju ključnih aktera."
#| fig-width: 10
#| fig-height: 8
set.seed(42)
# priprema mrežnih podataka s atributima za vizualizaciju
demo_data <- sample_islands(islands.n = 4, islands.size = 15, islands.pin = 0.35, n.inter = 4) |>
as_tbl_graph() |>
mutate(
name = paste0("N", row_number()),
community = as.factor(group_louvain()),
centrality = centrality_degree(),
betweenness = centrality_betweenness()
)
# vizualizacija pomoću ggraph s mapiranjem atributa na vizualne dimenzije
ggraph(demo_data, layout = "fr") +
geom_edge_link(alpha = 0.2, color = "gray50") +
geom_node_point(aes(size = centrality, color = community), alpha = 0.8) +
geom_node_text(aes(label = ifelse(centrality > quantile(centrality, 0.9), name, "")),
repel = TRUE, size = 3) +
scale_size_continuous(range = c(2, 10), name = "Stupanj") +
scale_color_brewer(palette = "Set1", name = "Zajednica") +
labs(
title = "Mrežna vizualizacija s označenim zajednicama i centralnim akterima",
subtitle = "Veličina čvora prema stupnju, boja prema zajednici"
) +
theme_void() +
theme(legend.position = "bottom")
```
Vizualizacija omogućuje intuitivan uvid u mrežnu strukturu, no svaka analiza mreža suočava se s temeljnim metodološkim izazovima koji mogu utjecati na valjanost zaključaka. Upravo ti izazovi razmatraju se u završnom odjeljku ovog poglavlja.
# Metodološki problemi i ograničenja
Analiza društvenih mreža pruža moćan konceptualni i metodološki aparat za razumijevanje relacijskih fenomena, no kao i svaka istraživačka metoda, suočava se s nizom izazova koji zahtijevaju pažljivu refleksiju i transparentno dokumentiranje. Ovi izazovi sežu od temeljnih konceptualnih pitanja o definiciji mreže do praktičnih problema s kvalitetom podataka i etičkim dilemama.
## Problem granica
Svaka mrežna analiza započinje fundamentalnom odlukom: koji akteri i koje veze čine mrežu koju proučavamo? Ova naizgled jednostavna pitanja kriju duboke konceptualne i praktične izazove poznate kao **problem granica** (engl. *boundary specification problem*). Odluka o granicama mreže izravno utječe na sve izračunate mjere, jer uključivanje ili isključivanje čak i malog broja čvorova može značajno promijeniti distribucije centralnosti, gustoću i detektirane zajednice. Istraživač mora donijeti jasnu i teorijski opravdanu odluku o tome koje aktere uključiti, dokumentirati kriterije odabira i po mogućnosti provesti analize osjetljivosti kojima se ispituje kako promjene granica utječu na ključne nalaze.
```{r}
#| label: fig-boundary-problem
#| fig-cap: "Ilustracija problema granica. Crtkana linija označava arbitrarno postavljenu granicu mreže. Čvorovi na granici (narančasto) i izvan granice (sivo) mogu značajno utjecati na izračunate mjere za čvorove unutar granice."
#| fig-width: 10
#| fig-height: 7
set.seed(42)
# generiranje mreže za ilustraciju problema granica
full_net <- sample_gnp(30, 0.15)
# podjela čvorova u tri zone
core_nodes <- 1:20
boundary_nodes <- 21:25
external_nodes <- 26:30
# označavanje zona različitim bojama
V(full_net)$type <- case_when(
1:30 %in% core_nodes ~ "Unutar granice",
1:30 %in% boundary_nodes ~ "Na granici",
TRUE ~ "Izvan granice"
)
V(full_net)$color <- case_when(
V(full_net)$type == "Unutar granice" ~ "#3498db",
V(full_net)$type == "Na granici" ~ "#f39c12",
TRUE ~ "#bdc3c7"
)
# prilagodba rasporeda za jasniju vizualizaciju
set.seed(42)
layout_coords <- layout_with_fr(full_net)
layout_coords[core_nodes, ] <- layout_coords[core_nodes, ] * 0.6
layout_coords[external_nodes, 1] <- layout_coords[external_nodes, 1] + 2
plot(full_net,
layout = layout_coords,
vertex.size = 15,
vertex.frame.color = NA,
vertex.label = NA,
edge.color = adjustcolor("gray50", alpha = 0.5),
edge.width = 1.5,
main = "Problem granica: Gdje završava mreža?")
# crtanje granice mreže
theta <- seq(0, 2*pi, length.out = 100)
boundary_x <- cos(theta) * 1.3
boundary_y <- sin(theta) * 1.1
lines(boundary_x, boundary_y, lty = 2, lwd = 2, col = "#e74c3c")
legend("bottomleft",
legend = c("Unutar granice", "Na granici", "Izvan granice", "Granica mreže"),
col = c("#3498db", "#f39c12", "#bdc3c7", "#e74c3c"),
pch = c(16, 16, 16, NA),
lty = c(NA, NA, NA, 2),
lwd = c(NA, NA, NA, 2),
bty = "n")
```
## Nedostajući podaci
**Nedostajući podaci** (engl. *missing data*) predstavljaju sveprisutan problem u mrežnoj analizi koji može značajno iskriviti izračunate mjere i dovesti do pogrešnih zaključaka. Za razliku od klasičnih statističkih analiza gdje nedostajuće opservacije utječu samo na pojedine varijable, u mrežnoj analizi nedostajući čvor ili veza utječe na mjere svih okolnih čvorova. Nedostatak jedne veze može promijeniti najkraće putanje između mnogih parova čvorova, utječući na mjere međuposredovanja i bliskosti za cijelu mrežu.
```{r}
#| label: fig-missing-data-effect
#| fig-cap: "Efekt nasumično nedostajućih podataka na mrežne mjere. S porastom udjela nedostajućih veza, gustoća i prosječni stupanj linearno opadaju, dok je klasteriranje osjetljivije i može opadati nelinearno."
#| fig-width: 10
#| fig-height: 6
set.seed(42)
# generiranje polazne mreže malog svijeta
original_net <- sample_smallworld(dim = 1, size = 50, nei = 4, p = 0.1)
# definiranje raspona udjela nedostajućih podataka
missing_proportions <- seq(0, 0.4, by = 0.05)
# priprema podatkovnog okvira za rezultate
results <- data.frame(
udio_nedostajucih = numeric(),
gustoca = numeric(),
prosj_stupanj = numeric(),
klasteriranje = numeric()
)
# izračun referentnih vrijednosti za potpunu mrežu
original_density <- edge_density(original_net)
original_degree <- mean(degree(original_net))
original_clustering <- transitivity(original_net, type = "global")
# simulacija efekta nedostajućih podataka
for (prop in missing_proportions) {
temp_net <- original_net
n_edges <- ecount(temp_net)
n_remove <- floor(prop * n_edges)
if (n_remove > 0) {
remove_edges <- sample(1:n_edges, n_remove)
temp_net <- delete_edges(temp_net, remove_edges)
}
results <- rbind(results, data.frame(
udio_nedostajucih = prop,
gustoca = edge_density(temp_net) / original_density,
prosj_stupanj = mean(degree(temp_net)) / original_degree,
klasteriranje = transitivity(temp_net, type = "global") / original_clustering
))
}
# pretvaranje u dugi format za vizualizaciju
results_long <- results |>
pivot_longer(cols = -udio_nedostajucih,
names_to = "Mjera", values_to = "Relativna_vrijednost")
results_long$Mjera <- factor(results_long$Mjera,
levels = c("gustoca", "prosj_stupanj", "klasteriranje"),
labels = c("Gustoća", "Prosječni stupanj", "Klasteriranje"))
ggplot(results_long, aes(x = udio_nedostajucih * 100, y = Relativna_vrijednost * 100,
color = Mjera, shape = Mjera)) +
geom_line(linewidth = 1.2) +
geom_point(size = 3) +
scale_color_manual(values = c("#3498db", "#2ecc71", "#9b59b6")) +
geom_hline(yintercept = 100, linetype = "dashed", color = "gray50") +
labs(
title = "Osjetljivost mrežnih mjera na nedostajuće podatke",
subtitle = "Relativne vrijednosti u odnosu na potpunu mrežu (100% = izvorna vrijednost)",
x = "Udio nasumično uklonjenih veza (%)",
y = "Relativna vrijednost mjere (%)",
color = NULL, shape = NULL
) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom") +
ylim(0, 120)
```
## Etički izazovi
Mrežni podaci nose posebne etičke izazove koji nadilaze standardne etičke protokole društvenih istraživanja. Fundamentalna tenzija proizlazi iz činjenice da mrežna analiza inherentno uključuje podatke o odnosima između ljudi. Čak i ako pojedinac pristane na sudjelovanje u istraživanju, njegovi mrežni podaci neizbježno otkrivaju informacije o osobama s kojima je povezan, a koje možda nisu dale pristanak. Nadalje, mrežna vizualizacija može omogućiti identifikaciju specifičnih pojedinaca čak i kada su imena anonimizirana jer strukturna pozicija u mreži može biti jednako identifikacijska kao i ime. Ovi izazovi zahtijevaju posebnu pažnju pri dizajnu istraživanja, prikupljanju podataka i izvještavanju rezultata. Detaljnija razmatranja etičkih načela u društvenim istraživanjima, uključujući specifična pitanja digitalnih istraživanja, privatnosti i informiranog pristanka, obrađena su u poglavlju 13.
```{r}
#| label: tbl-methodology-summary
#| tbl-cap: "Sažetak ključnih metodoloških izazova u analizi društvenih mreža s preporukama za istraživače."
# tablica s pregledom metodoloških izazova i preporuka
methodology_summary <- data.frame(
Izazov = c(
"Problem granica",
"Nedostajući podaci",
"Etički izazovi"
),
Kljucno_pitanje = c(
"Koje aktere i veze uključiti u mrežu?",
"Kako postupati s nepotpunim podacima?",
"Kako zaštititi privatnost uz znanstvenu vrijednost?"
),
Potencijalne_posljedice = c(
"Različite granice daju različite nalaze",
"Iskrivljene mjere, pogrešni zaključci",
"Šteta za sudionike, gubitak povjerenja"
),
Kljucne_preporuke = c(
"Transparentnost, teorijsko opravdanje, analize osjetljivosti",
"Procjena opsega, robusnost nalaza, dokumentiranje ograničenja",
"Minimizacija podataka, agregacija, napredne tehnike zaštite"
)
)
# formatiranje tablice
kable(methodology_summary,
col.names = c("Izazov", "Ključno pitanje", "Potencijalne posljedice", "Ključne preporuke")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Svaki od navedenih izazova zahtijeva eksplicitno dokumentiranje u istraživačkom izvještaju kako bi čitatelji mogli procijeniti valjanost i pouzdanost mrežne analize.
Metodološka rigoroznost u mrežnoj analizi zahtijeva kontinuiranu refleksiju o odlukama koje oblikuju istraživanje. Problem granica podsjeća da svaka mreža koja se analizira jest konstrukcija nastala iz istraživačevih odluka o tome što uključiti. Nedostajući podaci upozoravaju da podaci nikada nisu potpuni i da je potrebno razumjeti kako ta nepotpunost utječe na zaključke. Etički izazovi naglašavaju da iza svakog čvora i svake veze stoje stvarni ljudi čiju privatnost valja poštivati.
# Cjelovit primjer: analiza komunikacijske mreže
Svi koncepti obrađeni u prethodnim odjeljcima mogu se ilustrirati cjelovitim primjerom analize jedne komunikacijske mreže. Zamislimo istraživački projekt koji proučava mrežu dijeljenja vijesti među korisnicima društvene mreže tijekom predizbornog razdoblja u Hrvatskoj. Istraživačko pitanje glasi: kakva je struktura komunikacijske mreže i koji akteri zauzimaju ključne pozicije u širenju političkih informacija? Za potrebe ovog primjera koristi se sintetička mreža koja simulira tipične obrasce opažene u empirijskim istraživanjima komunikacijskih mreža.
```{r}
#| label: fig-end-to-end-network
#| fig-cap: "Cjelovit primjer analize komunikacijske mreže: vizualizacija mreže dijeljenja vijesti s označenim zajednicama i centralnim akterima. Veličina čvora proporcionalna je stupnju centralnosti, boja označava zajednicu, a oznake prikazuju najcentralnije aktere u svakoj zajednici."
#| fig-width: 11
#| fig-height: 9
set.seed(2024)
# generiranje sintetičke mreže s četiri zajednice
election_net <- sample_islands(
islands.n = 4,
islands.size = 20,
islands.pin = 0.25,
n.inter = 5
)
# detekcija zajednica i dodjela oznaka
election_communities <- cluster_louvain(election_net)
V(election_net)$community <- membership(election_communities)
community_labels <- c("Konzervativni mediji", "Progresivni mediji",
"Lokalni portali", "Nezavisni komentatori")
V(election_net)$community_label <- community_labels[V(election_net)$community]
# izračun svih mjera centralnosti
V(election_net)$degree <- degree(election_net)
V(election_net)$betweenness <- betweenness(election_net, normalized = TRUE)
V(election_net)$closeness <- closeness(election_net, normalized = TRUE)
V(election_net)$eigenvector <- eigen_centrality(election_net)$vector
# dodjela imena čvorovima
V(election_net)$name <- paste0("K", 1:vcount(election_net))
# boje prema zajednicama
community_colors <- c("#e74c3c", "#3498db", "#2ecc71", "#9b59b6")
V(election_net)$color <- community_colors[V(election_net)$community]
# oznake samo za najcentralnije čvorove
top_nodes <- which(V(election_net)$degree >= quantile(V(election_net)$degree, 0.85))
V(election_net)$label_show <- ifelse(1:vcount(election_net) %in% top_nodes,
V(election_net)$name, NA)
# vizualizacija cjelovitog primjera
set.seed(42)
plot(election_net,
layout = layout_with_fr,
vertex.size = sqrt(V(election_net)$degree) * 2.5 + 3,
vertex.frame.color = NA,
vertex.label = V(election_net)$label_show,
vertex.label.color = "black",
vertex.label.cex = 0.8,
vertex.label.dist = 1.5,
edge.color = adjustcolor("gray50", alpha = 0.3),
edge.width = 0.8,
main = "Mreža dijeljenja vijesti tijekom predizbornog razdoblja")
legend("bottomleft",
legend = community_labels,
fill = community_colors,
bty = "n",
title = "Zajednica")
```
Prvi korak analize uključuje izračun makrostrukturnih mjera koje karakteriziraju mrežu kao cjelinu. Gustoća mreže, koeficijent klasteriranja i prosječna duljina putanje zajedno pružaju sliku o tome koliko je mreža kohezivna, jesu li prisutne lokalne strukture zajednica i koliko je učinkovita globalna komunikacija.
```{r}
#| label: tbl-end-to-end-macro
#| tbl-cap: "Globalne mjere mrežne strukture za primjer mreže dijeljenja vijesti. Visok koeficijent klasteriranja uz kratku prosječnu putanju sugerira strukturu malog svijeta tipičnu za komunikacijske mreže."
# izračun i prikaz globalnih mjera mrežne strukture
macro_measures <- data.frame(
Mjera = c("Broj čvorova", "Broj veza", "Gustoća",
"Koeficijent klasteriranja", "Prosječna duljina putanje",
"Broj zajednica", "Modularnost"),
Vrijednost = c(
vcount(election_net),
ecount(election_net),
round(edge_density(election_net), 4),
round(transitivity(election_net, type = "global"), 3),
round(mean_distance(election_net), 2),
max(membership(election_communities)),
round(modularity(election_communities), 3)
),
Interpretacija = c(
"Veličina promatrane mreže",
"Ukupan broj interakcija",
"Relativno rijetka mreža, tipično za društvene mreže",
"Visoko lokalno klasteriranje, prisutne kohezivne grupe",
"Kratke putanje, učinkovita difuzija informacija",
"Jasno razdvojene zajednice",
"Snažna modularna struktura"
)
)
# formatiranje tablice
kable(macro_measures,
col.names = c("Mjera", "Vrijednost", "Interpretacija")) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Drugi korak analize fokusira se na identifikaciju ključnih aktera putem mjera centralnosti. Usporedba različitih mjera otkriva koji akteri su najvidljiviji (stupanj), koji kontroliraju tokove informacija (međuposredovanje), koji mogu najučinkovitije širiti poruke (bliskost) i koji imaju pristup elitnim krugovima (svojstvena vektorska centralnost).
```{r}
#| label: tbl-end-to-end-centrality
#| tbl-cap: "Deset najcentralnijih aktera u mreži prema stupnju centralnosti, s usporednim vrijednostima svih četiri mjere centralnosti. Razlike u rangiranju prema različitim mjerama otkrivaju različite aspekte utjecaja pojedinih aktera."
# priprema podataka za tablicu deset najcentralnijih aktera
top10_df <- data.frame(
Akter = V(election_net)$name,
Zajednica = V(election_net)$community_label,
Stupanj = V(election_net)$degree,
Meduposredovanje = round(V(election_net)$betweenness, 3),
Bliskost = round(V(election_net)$closeness, 3),
Eigenvector = round(V(election_net)$eigenvector, 3)
)
# sortiranje i odabir prvih deset
top10_df <- top10_df[order(-top10_df$Stupanj), ][1:10, ]
# formatiranje tablice
kable(top10_df,
col.names = c("Akter", "Zajednica", "Stupanj", "Međuposr.", "Bliskost", "Eigenvector"),
row.names = FALSE) |>
kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE)
```
Rezultati ovog cjelovitog primjera ilustriraju kako se različiti koncepti obrađeni u ovom poglavlju integriraju u koherentnu analizu. Globalne mjere pokazuju da mreža ima strukturu malog svijeta s visokim klasteriranjem i kratkim putanjama, što omogućuje brzu difuziju informacija. Snažna modularnost potvrđuje postojanje jasno razdvojenih zajednica, što može ukazivati na ideološku fragmentaciju javnog prostora. Mjere centralnosti identificiraju različite tipove ključnih aktera: neke je moguće identificirati kao popularne čvorove s mnogo veza, druge kao posrednike koji premošćuju strukturne rupe između zajednica. Praktična implikacija ovih nalaza za istraživače masovne komunikacije jest da se utjecaj pojedinačnih aktera ne može svesti na jednu dimenziju, već zahtijeva multidimenzionalni pristup koji uzima u obzir različite aspekte mrežne pozicije.
# Sažetak poglavlja
Ovo poglavlje pružilo je sustavan pregled analize društvenih mreža kao metodološkog pristupa u istraživanju masovne komunikacije. Polazište je bila relacijska perspektiva koja premješta fokus s individualnih atributa aktera na obrasce povezanosti među njima, otvarajući nove mogućnosti za razumijevanje fenomena poput širenja informacija, formiranja javnog mnijenja i dinamike medijskog utjecaja. Historijski razvoj mrežnog pristupa, od Morenove sociometrije preko Milgramovog eksperimenta malog svijeta do Barabasijevih mreža bez skale, pokazao je kako su ključna otkrića o strukturi društvenih odnosa postupno oblikovala suvremenu mrežnu znanost.
Osnovni elementi mreža, čvorovi i veze, definirani su zajedno s ključnim dimenzijama poput usmjerenosti i težine, te formatima za prikaz mrežnih podataka poput matrice susjedstva i liste bridova. Mjere centralnosti, uključujući stupanj, međuposredovanje, bliskost i svojstvenu vektorsku centralnost, operacionaliziraju različite koncepte važnosti aktera u mreži i omogućuju identifikaciju utjecajnih medija, gatekeepera i mostova između zajednica. Na makrorazini, gustoća, koeficijent klasteriranja, prosječna duljina putanje i distribucija stupnjeva pružaju uvide u globalnu organizaciju komunikacijskih sustava i procese koji ih oblikuju.
Analiza grupne strukture, od klika i homofilije do detekcije zajednica i teorije strukturnih rupa, omogućuje mapiranje fragmentacije javne sfere i razumijevanje dinamike unutar i između komunikacijskih zajednica. Vizualizacija mreža, premda se suočava s izazovom efekta dlakave lopte pri velikim mrežama, ostaje nezaobilazno sredstvo za komunikaciju mrežnih nalaza. Metodološki problemi poput definiranja granica mreže, nedostajućih podataka i etičkih dilema zahtijevaju transparentnost, rigoroznost i kontinuiranu refleksiju o odlukama koje oblikuju istraživanje.
U sljedećem poglavlju sustavno se obrađuju etička načela u znanstvenim istraživanjima, uključujući specifična pitanja informiranog pristanka, privatnosti i etičkih izazova digitalnih istraživanja koja su u ovom poglavlju tek naznačena u kontekstu mrežnih podataka. Poglavlje 13 pruža širi institucionalni i normativni okvir koji nadopunjuje metodološke smjernice iznesene u ovom poglavlju.